
最近用DeepSeek的朋友应该都发现了,这个 AI 工具现在经常卡得没法用,自从春节期间爆火以来,deepseek老是出现服务器繁忙,截止目前官方也一直没有完全解决这个问题,这对于日常需要使用AI的小伙伴来说是一个急需解决的问题了。

其实这个问题也很好解决,这里给大家总结了三大方案,以及每个方案的优缺点,各位可根据自己的需求选择:
1. 第三方Deepseek工具
| 优点 | 缺点 | 适用场景 |
|---|---|---|
| - 零门槛使用:无需注册API或配置环境 | - 功能受限:免费次数限制(如每日5-100次) | 轻量级日常查询、临时需求 |
| - 多终端支持:浏览器插件/APP/网页即开即用 | - 依赖第三方:服务稳定性受平台影响 | 非高频使用的普通用户 |
| - 内置优化:自带搜索增强/思考过程可视化 | - 隐私风险:数据需通过第三方服务器处理 | 需要快速获取答案的场景 |
2. Deepseek API调用
| 优点 | 缺点 | 适用场景 |
|---|---|---|
| - 灵活可控:自定义调用频率与参数 | - 技术门槛:需申请API Key并配置工具 | 开发者、企业级应用集成 |
| - 成本透明:按需付费,避免资源浪费 | - 潜在费用:高频使用可能累积较高成本 | 需要稳定接入的长期项目 |
| - 多模型切换:一键切换不同供应商的模型 | - 依赖网络:API服务商故障会导致中断 | 多模型对比测试场景 |
3. 本地化部署Deepseek
| 优点 | 缺点 | 适用场景 |
|---|---|---|
| - 完全离线:不受网络和服务商稳定性影响 | - 硬件要求高:需8GB+内存支持基础模型运行 | 敏感数据处理、隐私优先场景 |
| - 数据安全:对话内容与知识库本地存储 | - 性能妥协:仅能运行量化/蒸馏版小模型 | 企业内网环境、定制化需求 |
| - 长期稳定:一次部署后可持续使用 | - 部署复杂:需命令行操作或工具配置经验 | 技术团队或有一定开发能力者 |
综合对比与选择建议
| 方案优先级 | 推荐人群 | 核心考量因素 |
|---|---|---|
| 1 → 2 → 3 | 普通用户、临时需求 | 便捷性 > 成本 > 稳定性 |
| 2 → 3 → 1 | 开发者、企业应用 | 灵活性 > 可控性 > 数据安全 |
| 3 → 2 → 1 | 隐私敏感场景、高频内部使用 | 安全性 > 长期稳定性 > 硬件投入成本 |
下面我们来给大家详细介绍一下这三个替代方案:
一、第三方在线工具
1.纳米AI助手:https://bot.n.cn/
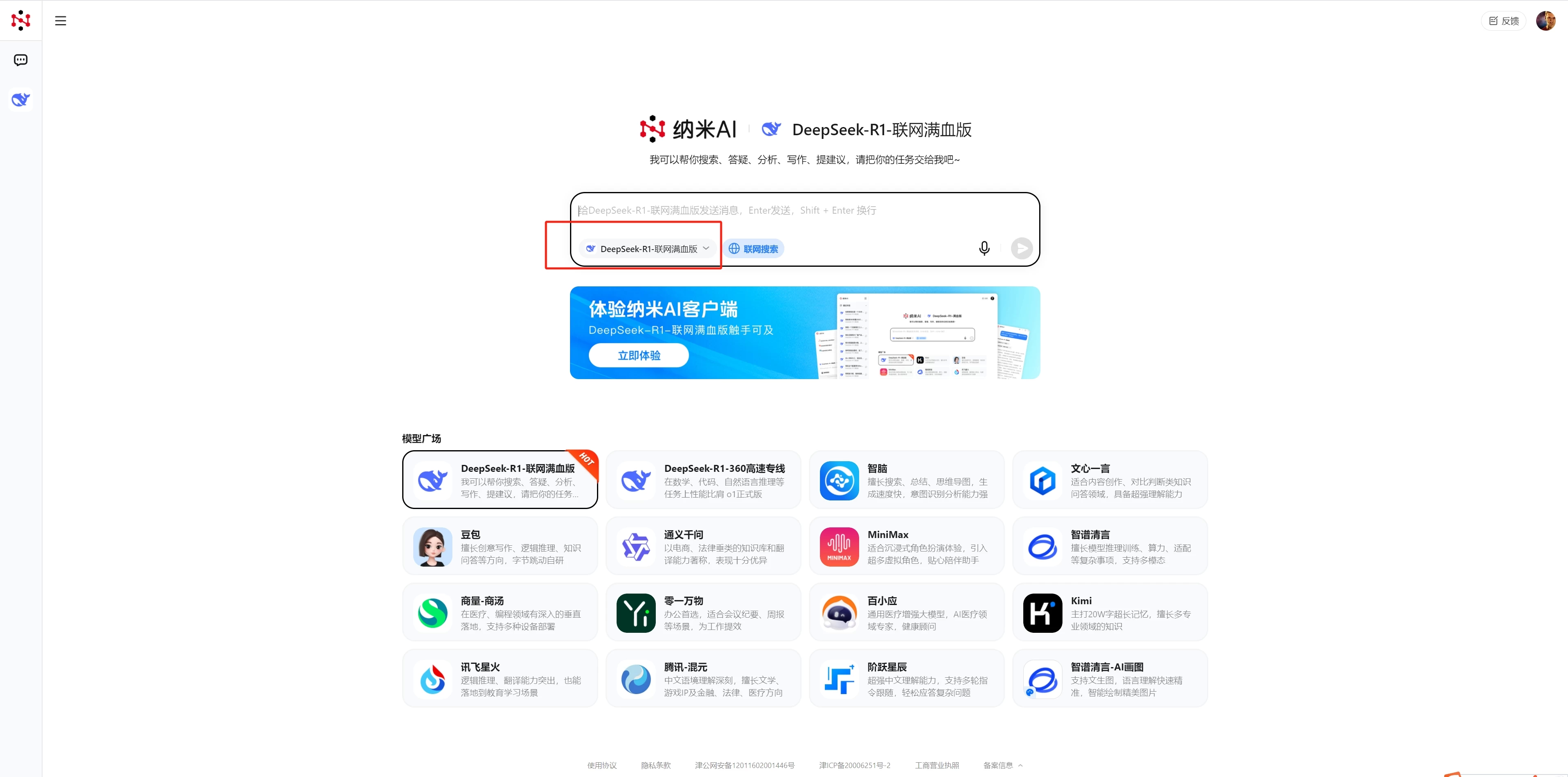
2.字节跳动火山引擎:https://console.volcengine.com/ark/region:ark+cn-beijing/experience
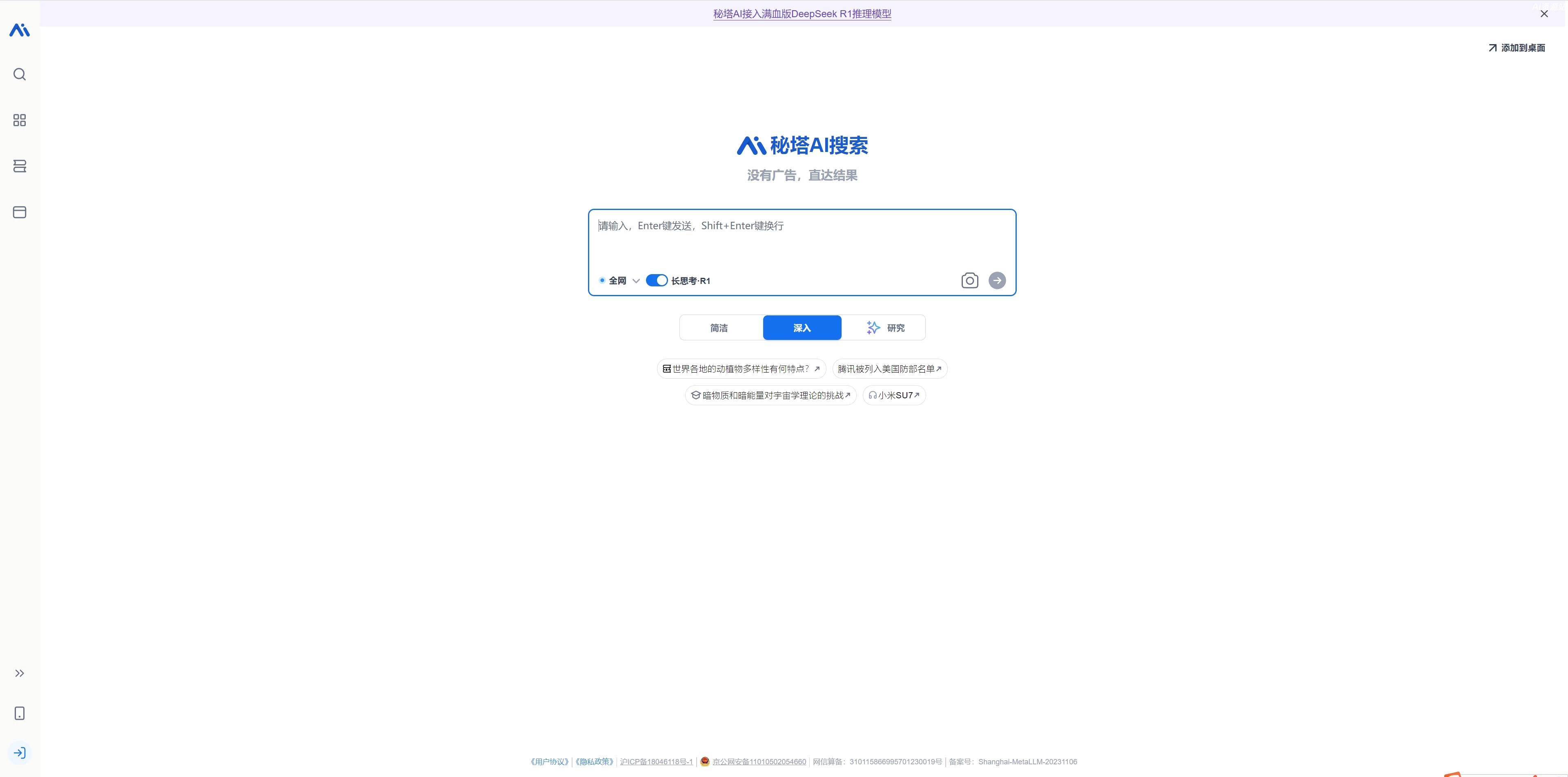
3.秘塔AI搜索:https://metaso.cn/
4.超算互联网:https://chat.scnet.cn/

5.硅基流动:https://account.siliconflow.cn/zh/login
6.Monica:https://monica.im/
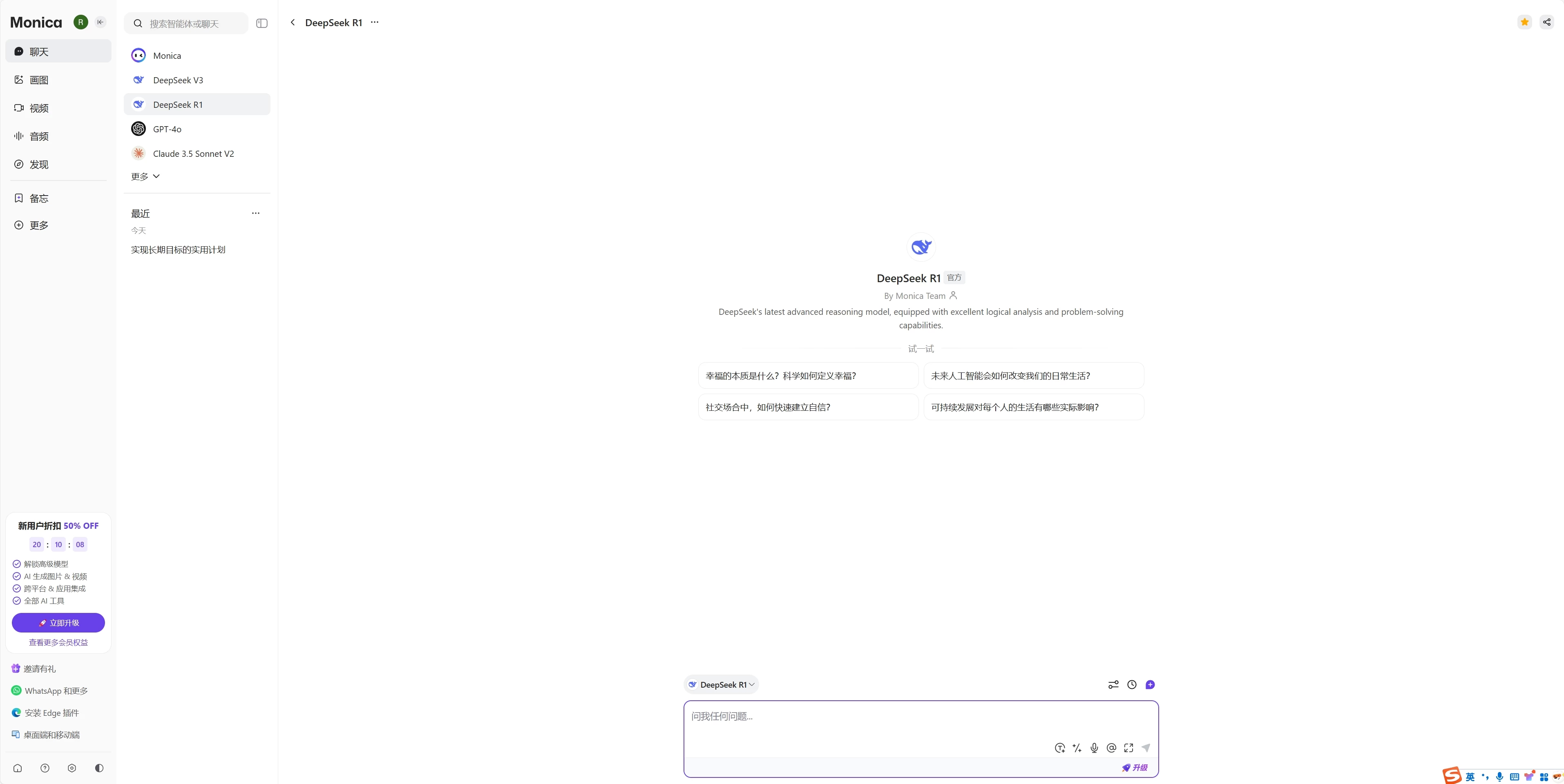
这6个非常容易上手的第三方在线工具,有免费也有收费,以下是这6个工具我们测试后总结的优缺点,大家可根据自己的需求来选择:
| 服务平台 | 优缺点 | 适用场景 | 优先级建议 |
|---|---|---|---|
| 纳米AI助手 | ✓ 网页版限时免费,app版20纳米/次 ✗ 思考速度有点慢,能接受 | 非紧急任务处理 | ⭐⭐⭐⭐⭐ |
| 火山引擎 | ✓ 注册送50万tokens/模型 ✗ 赠送的token较少 | 开发者初期测试 | ⭐⭐⭐⭐☆ |
| 秘塔AI搜索 | ✓ 中文友好+100次/日 ✗ 不适合文本对话 | 纯搜索类任务 | ⭐⭐⭐⭐ |
| 超算互联网 | ✓ 免费免注册 ✗ 32B模型 vs 原版671B,不能联网 | 基础问答/快速验证 | ⭐⭐⭐☆ |
| 硅基流动 | ✓ 送2000万tokens ✗ 常卡顿,Pro版收费(输入4元/百万tokens,输出16元/百万tokens) | 高token消耗项目 | ⭐⭐⭐ |
| Monica | ✓ 多终端+可视化思考 ✗ 35秒响应,免费40次/日 | 多设备协同/教学演示 | ⭐⭐☆ |
二、API调用
用Deepseek的API搭配支持多模型服务的桌面客户端软件,可以轻松快速使用Deepseek。
我们测试了一些提供deepseek API的平台,挑选出4款,都是大厂出品,相对有保证。那有了API,该怎么使用呢?这里推荐一个开源免费的工具:Cherry Studio ,这是一款多模型 AI 客户端,支持多种API,可集成多种主流 AI 模型,实现云端和本地模型自由切换,还内置 300 + 预配置 AI 助手,涵盖多领域,功能强大。
Cherry Studio下载地址:https://cherry-ai.com/download
下载安装打开后如图:
1.官方API:https://platform.deepseek.com
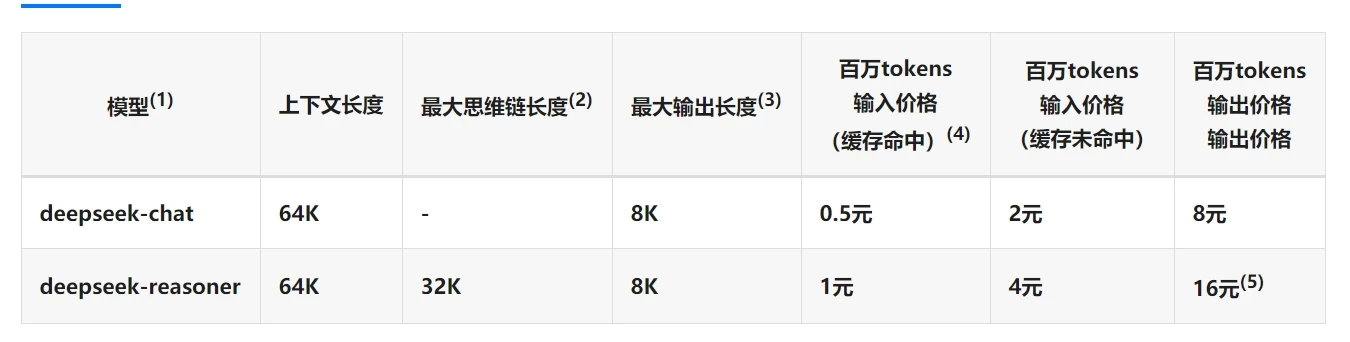
注册赠送10元额度,下图是付费的价格
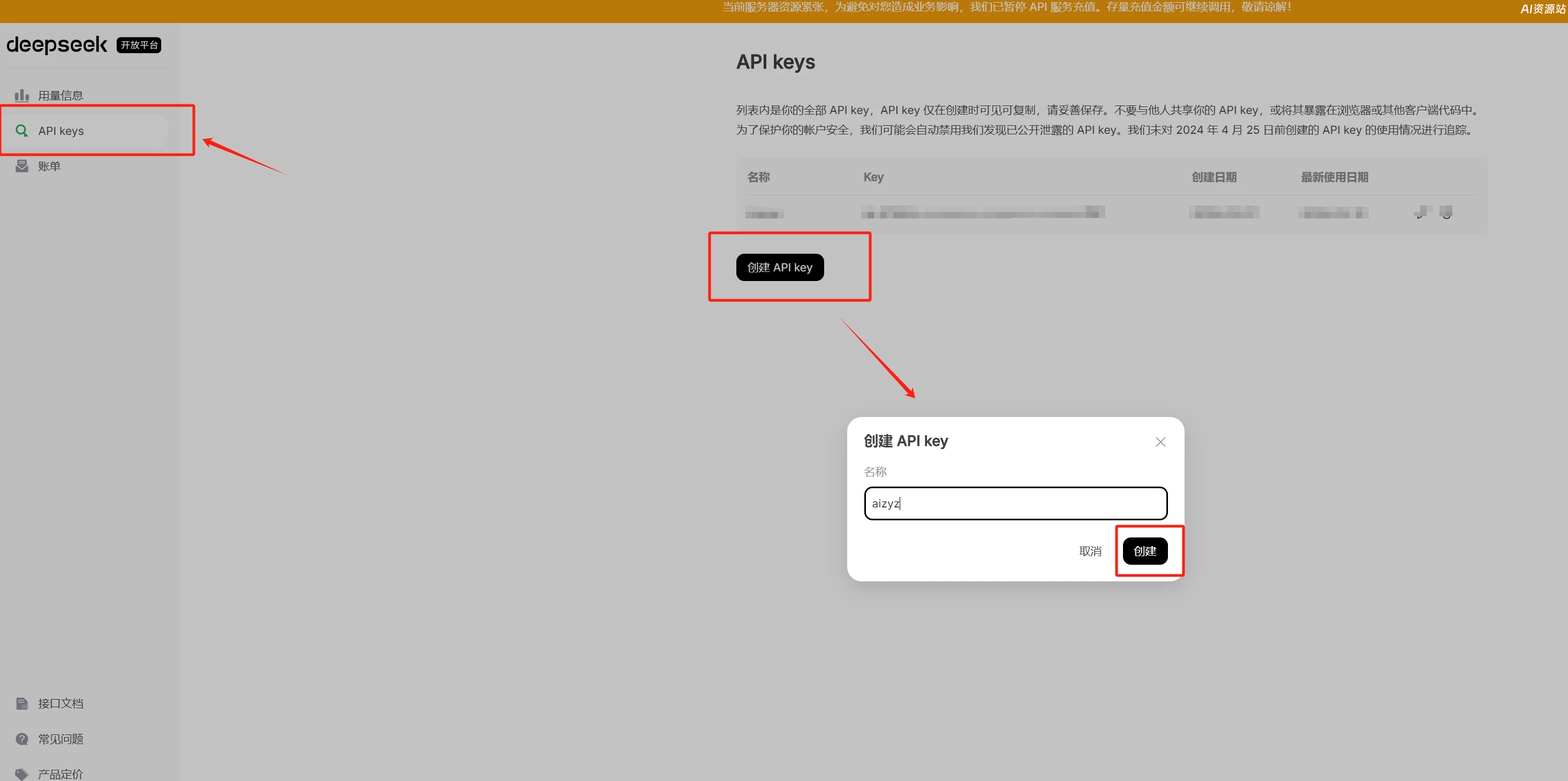
官方API获取方式:打开官方API的后台地址,创建API
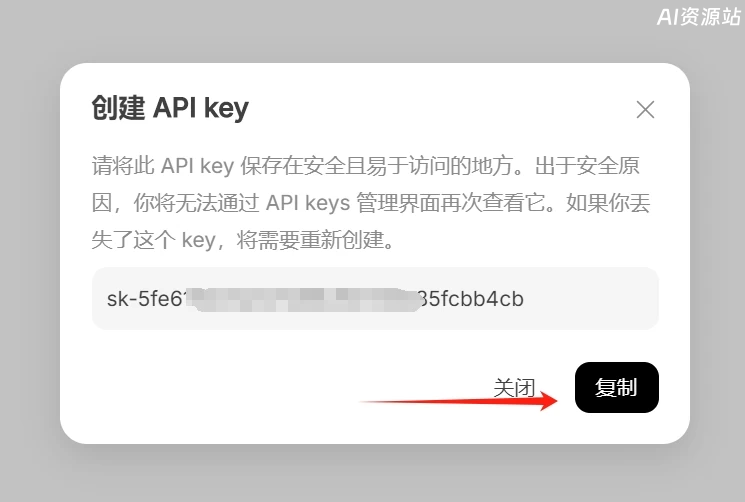
复制创建好的API,打开Cherry Studio,点击左下角的设置图标,如下图
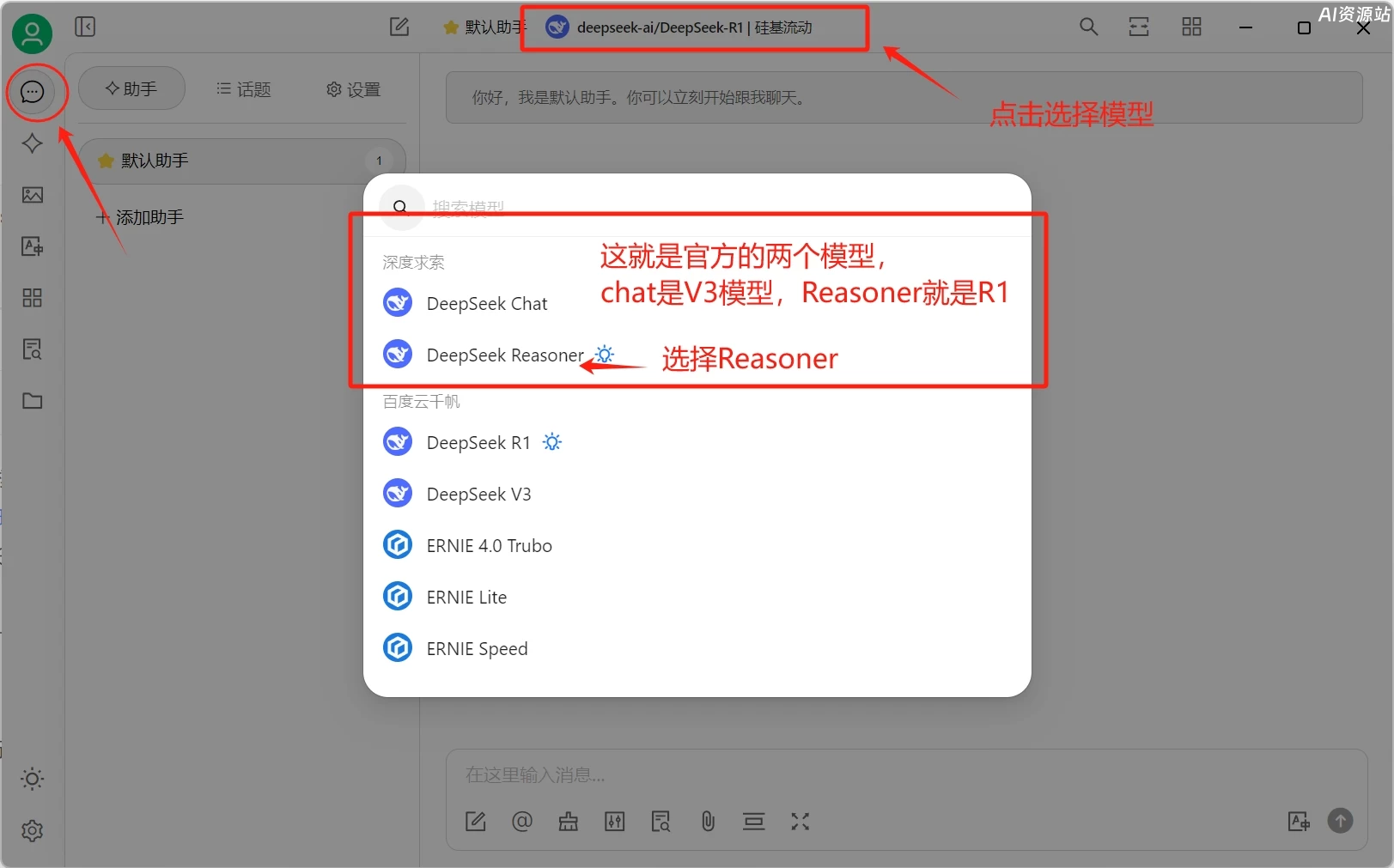
这样就可以正常使用Deepseek R1模型了!
2.火山引擎:https://console.volcengine.com/ark/region:ark+cn-beijing/experience
注册免费赠送50万tokens,2元/百万输入tokens,8元/百万输出tokens
火山引擎API使用:首先打开上面的链接,开通deepseek的服务
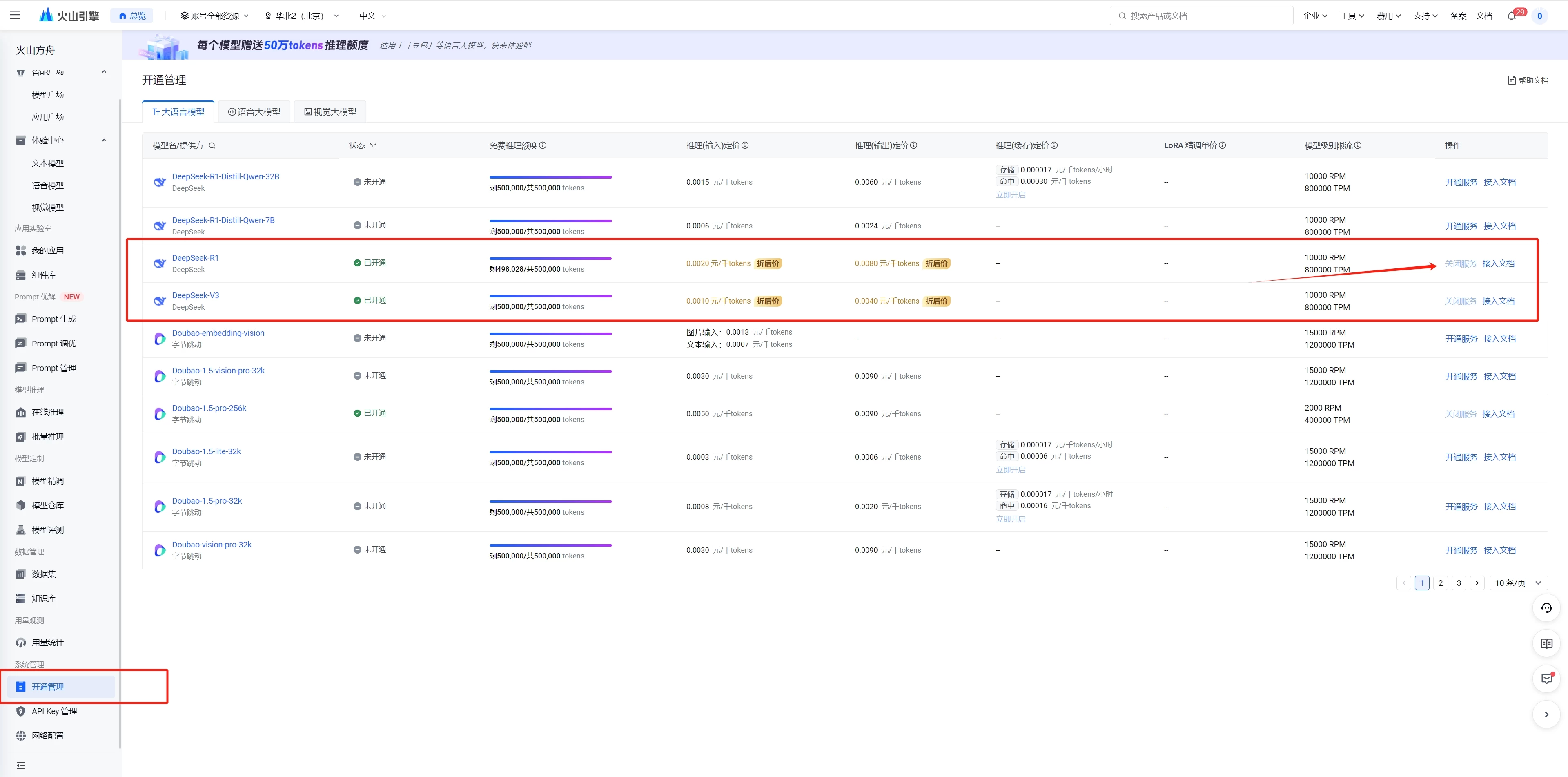
开通后,创建推理接入点
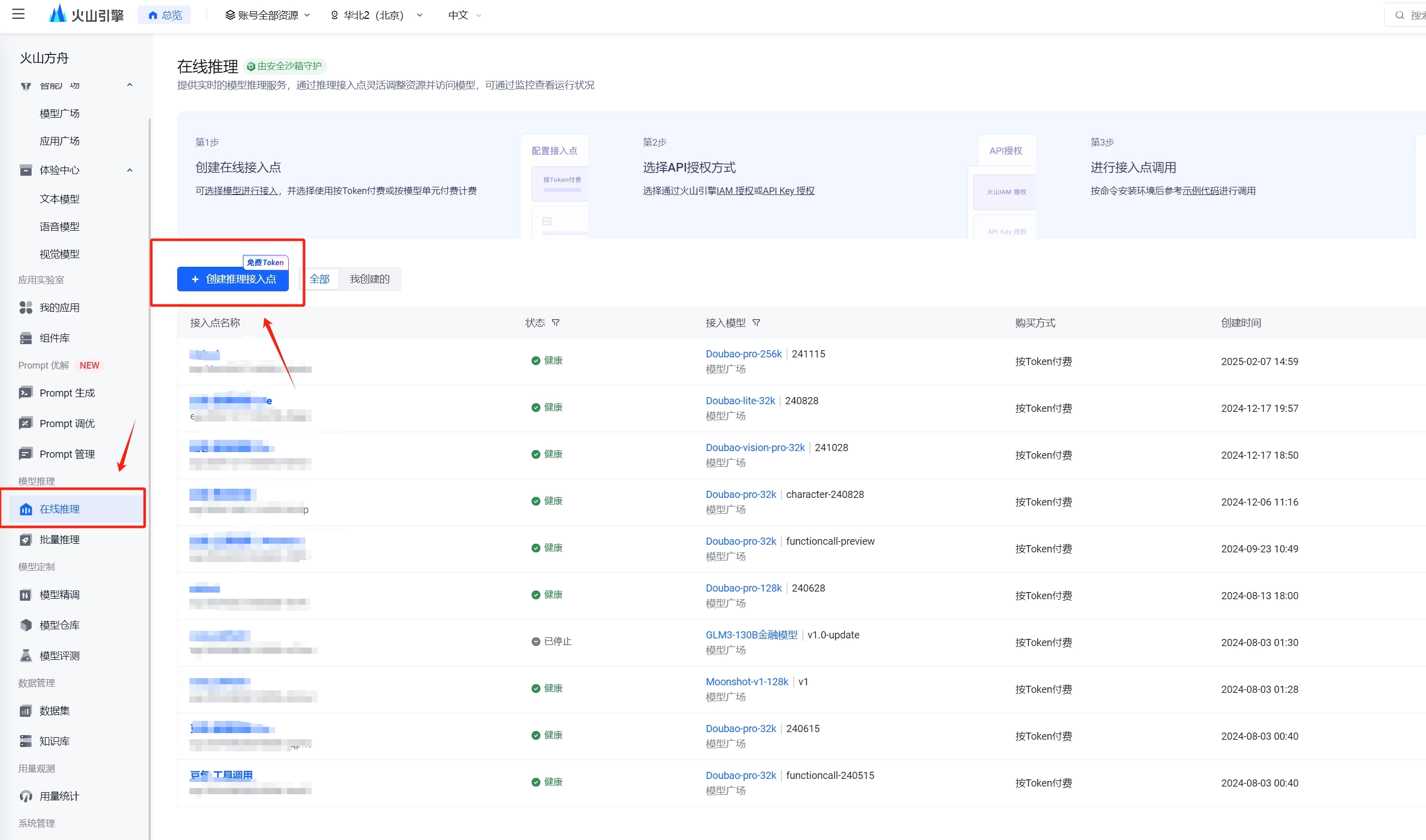
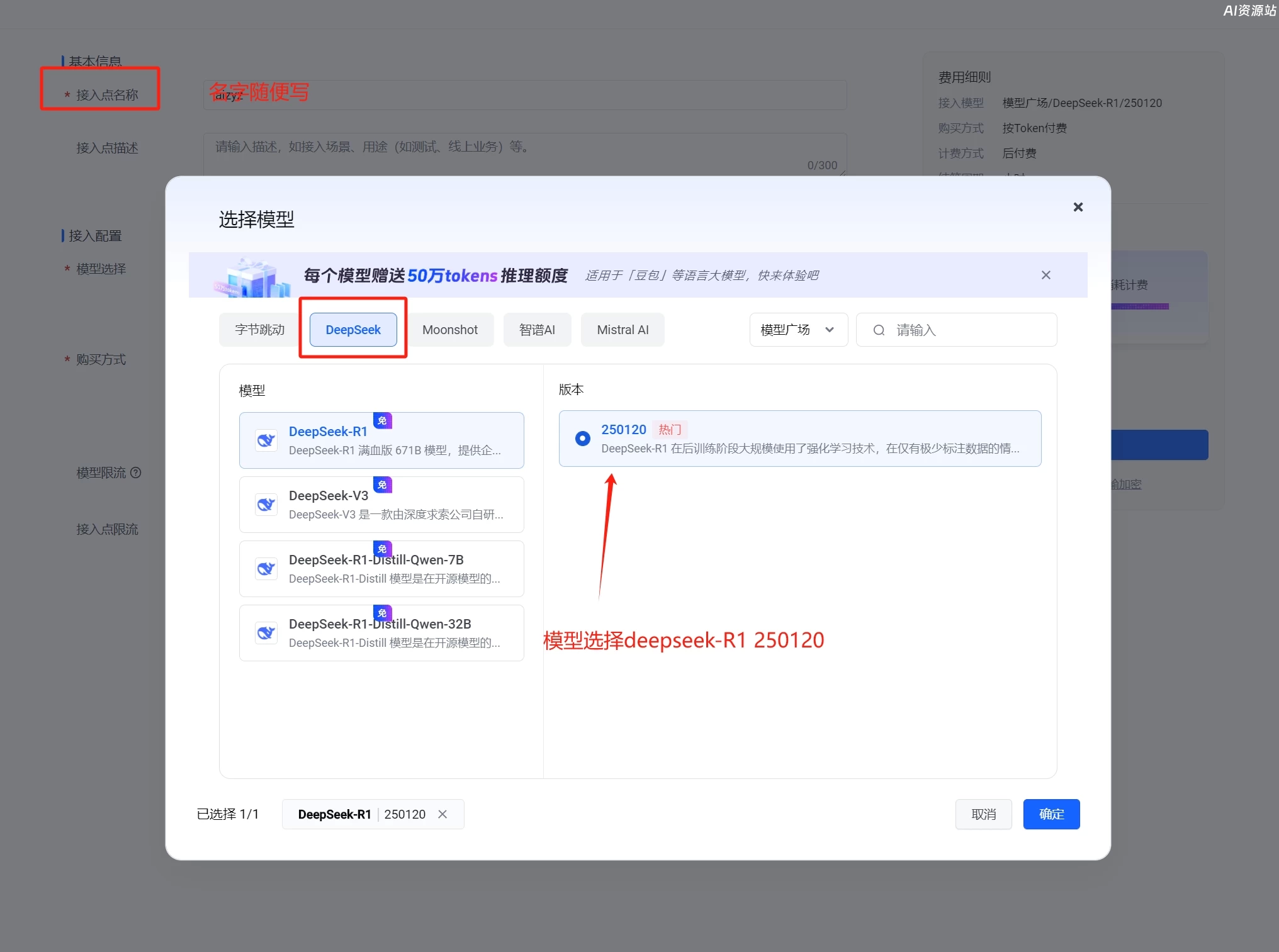
接下来我们再来创建一个API KEY
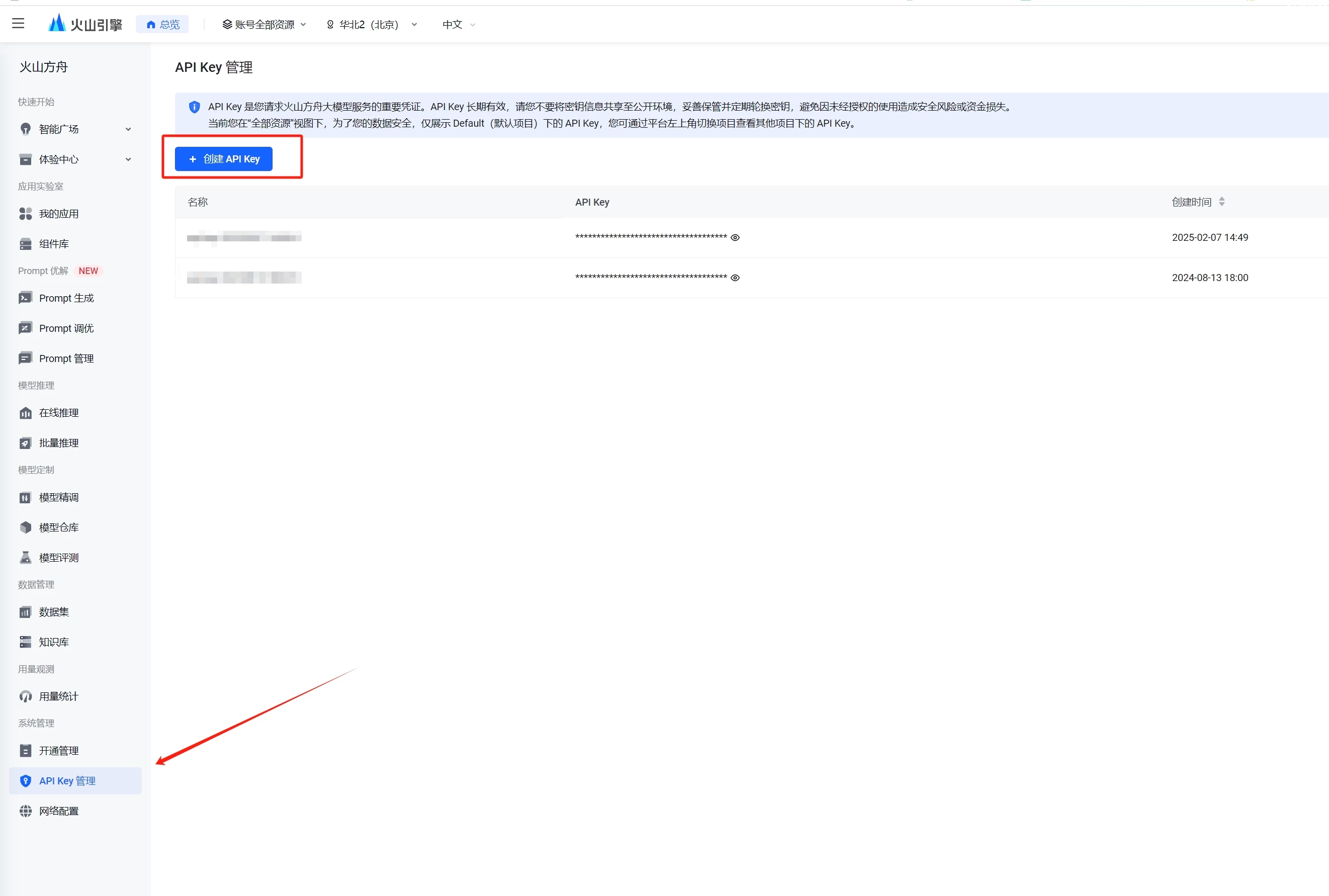
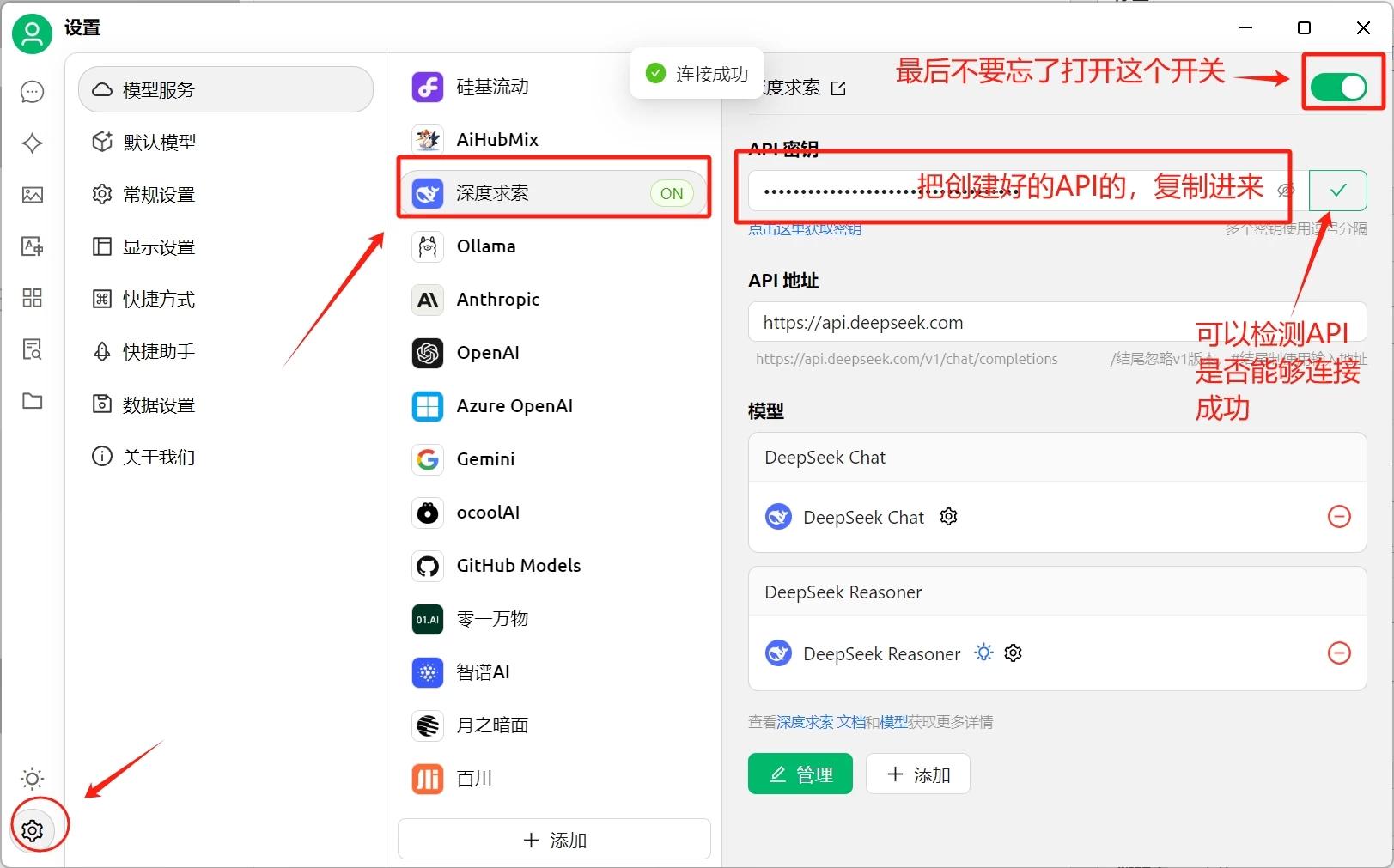
然后复制创建好的API key

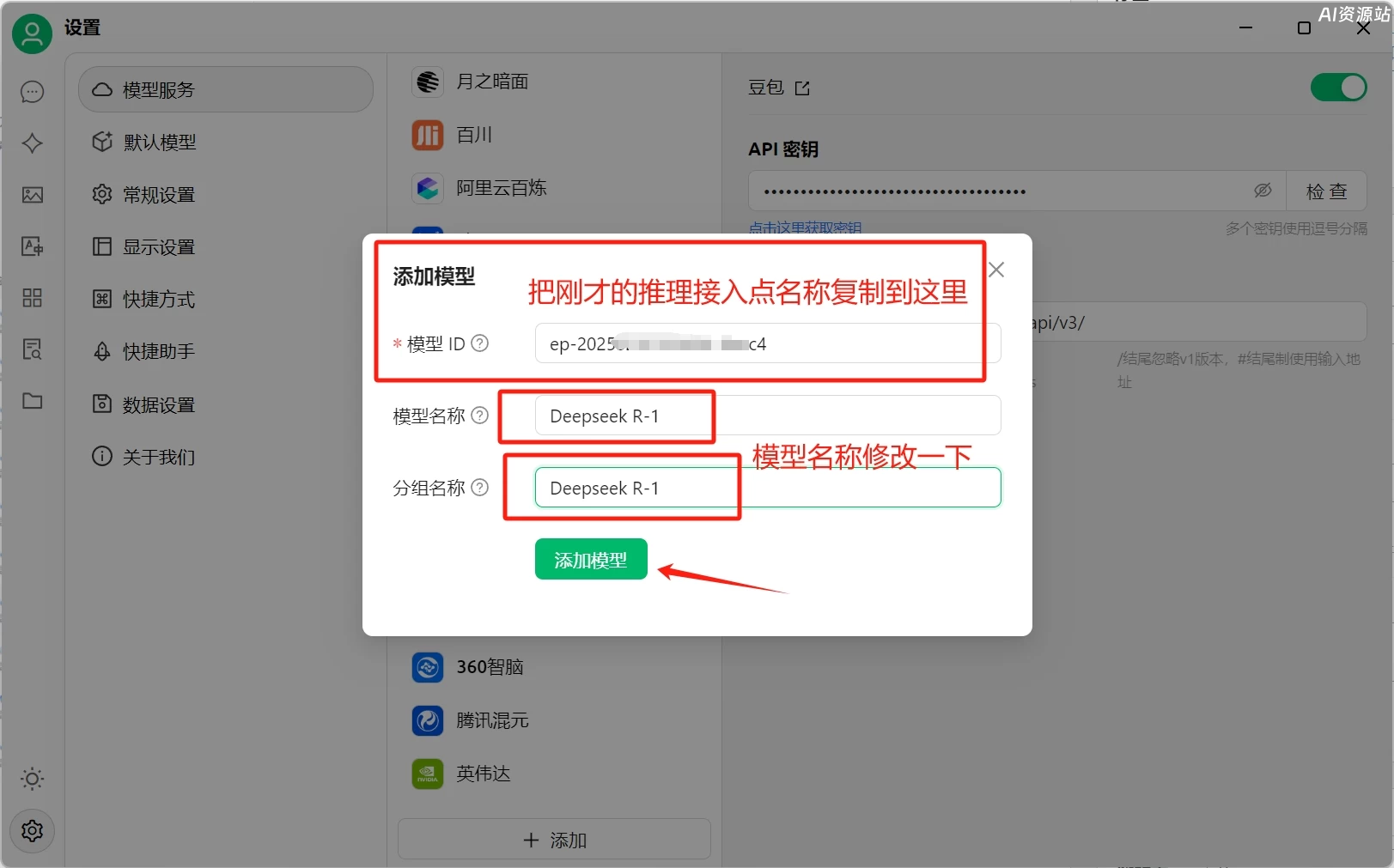
打开CherryStudio的设置,选择豆包,将复制的KEY粘贴到API秘钥这里
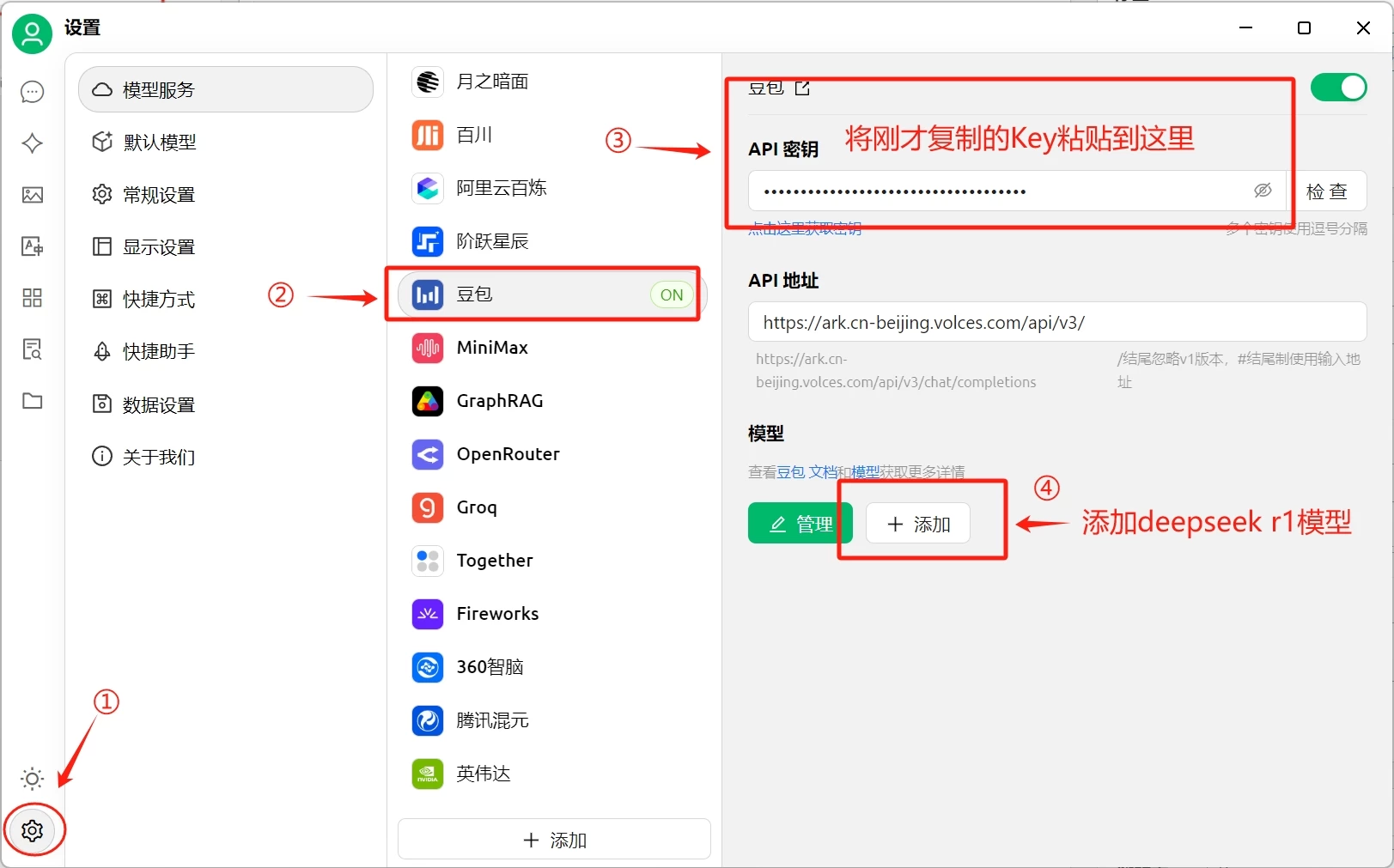
接下来我们还要添加deepseek r1模型,上图第四部,点击添加,然后回到火山引擎的网页,复制在线推理接入点的名称
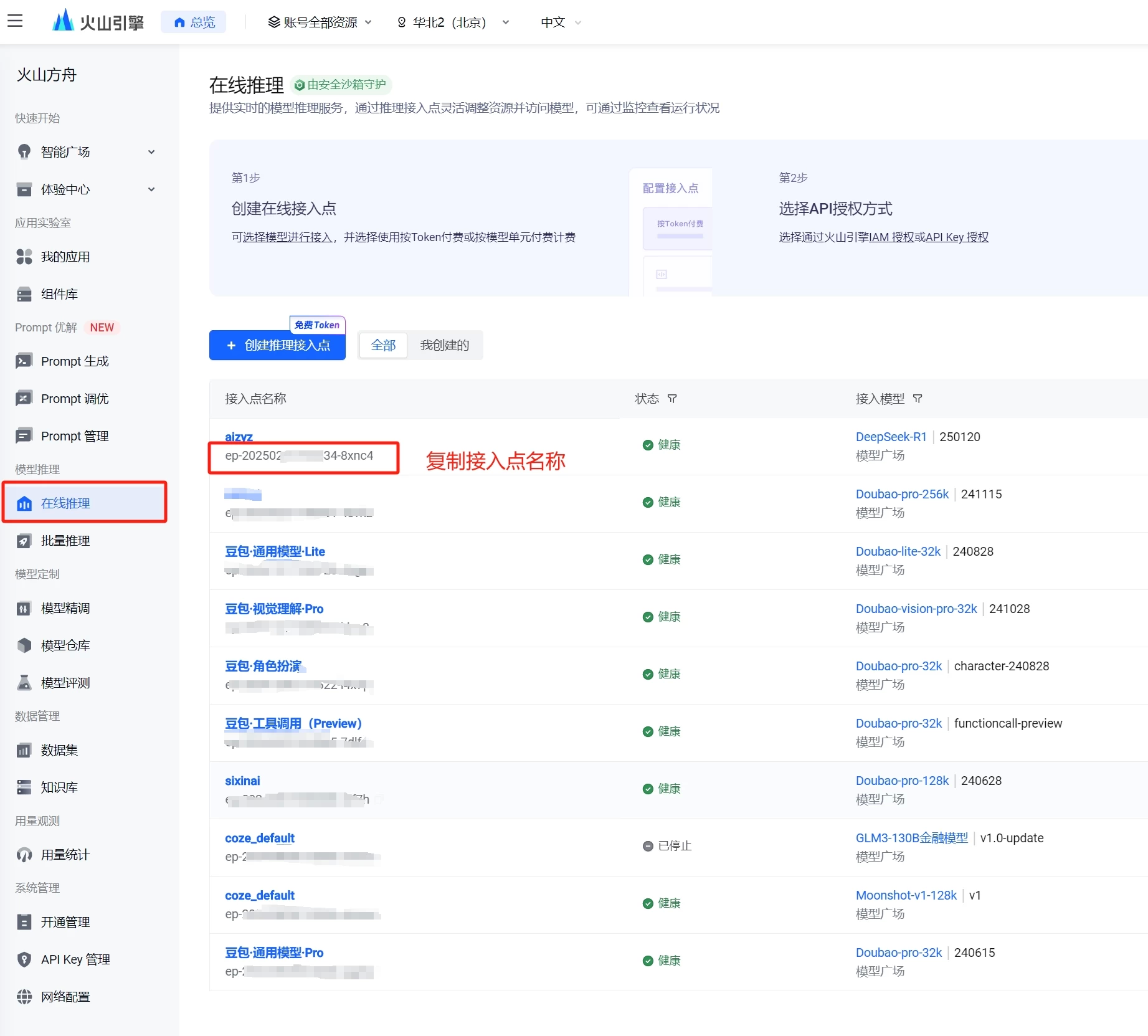
复制好后粘贴到刚才CherryStudio的添加模型窗口的“模型ID”中
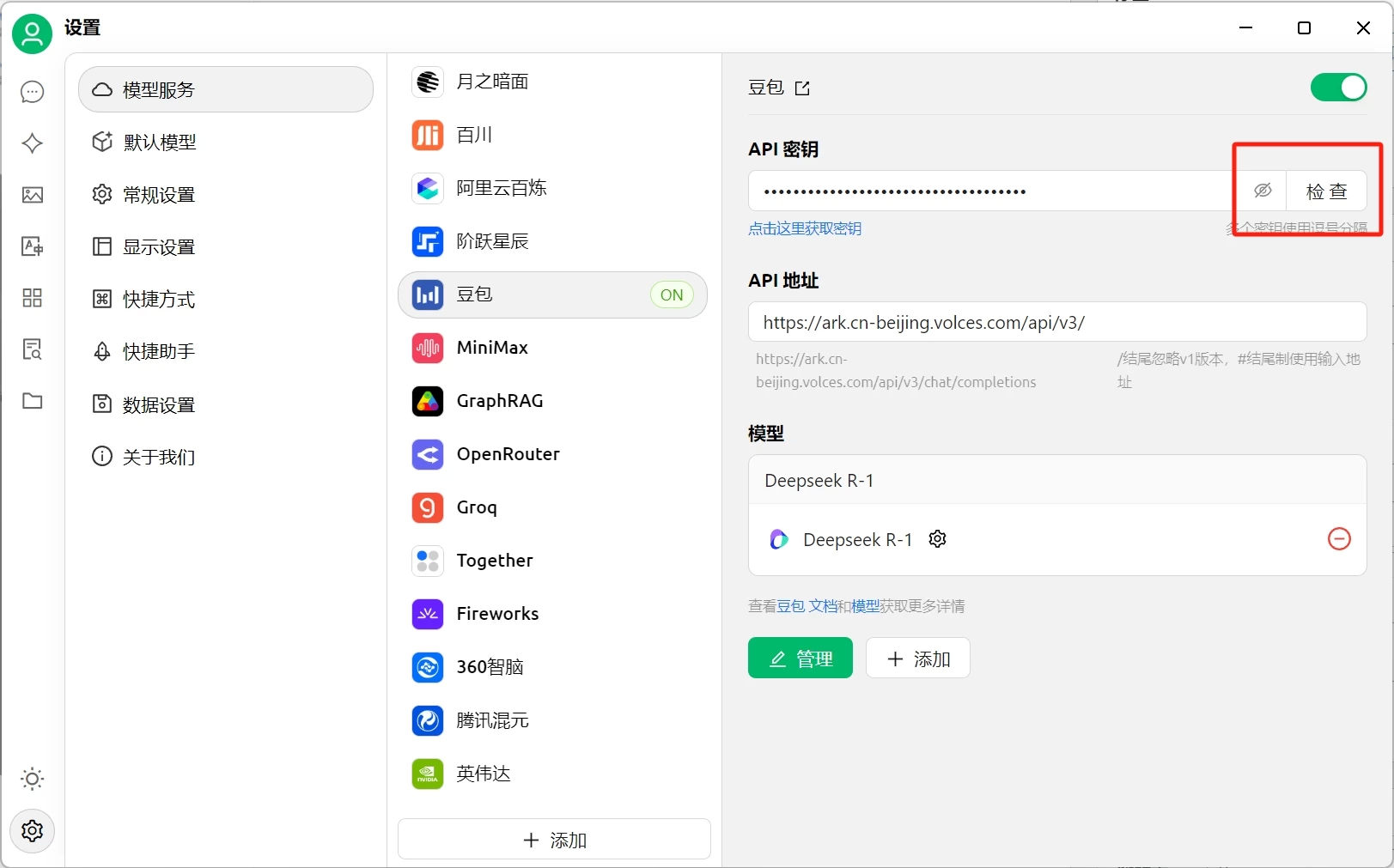
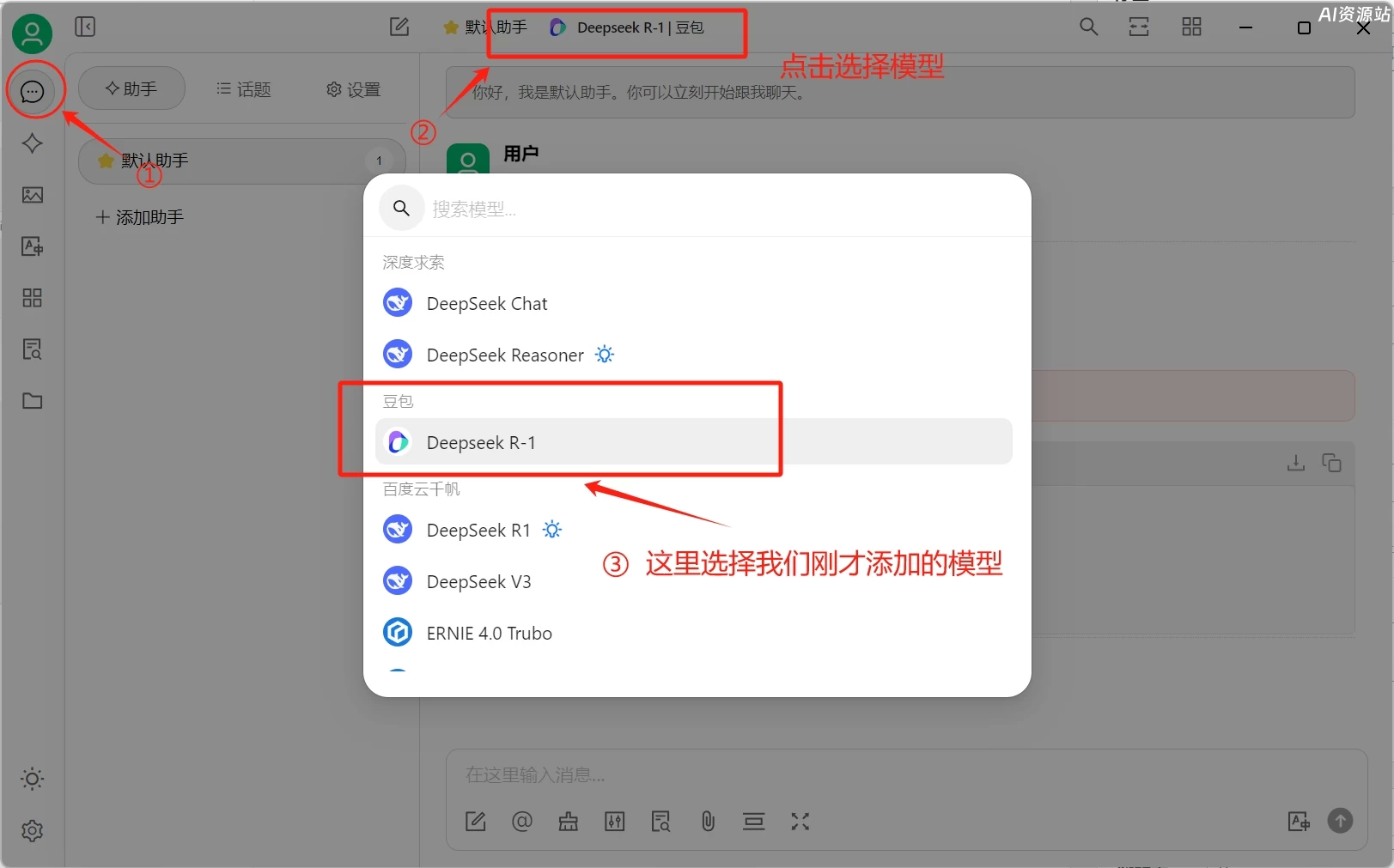
添加完可以点击“检查”测试一下连接是否成功,如果没有问题,回到对话页面选择我们刚才添加的模型就可以正常使用了。
3.腾讯云:https://console.cloud.tencent.com/lkeap
限时免费至2025.02.25
腾讯云API创建方式,打开网页登录成功后创建API KEY

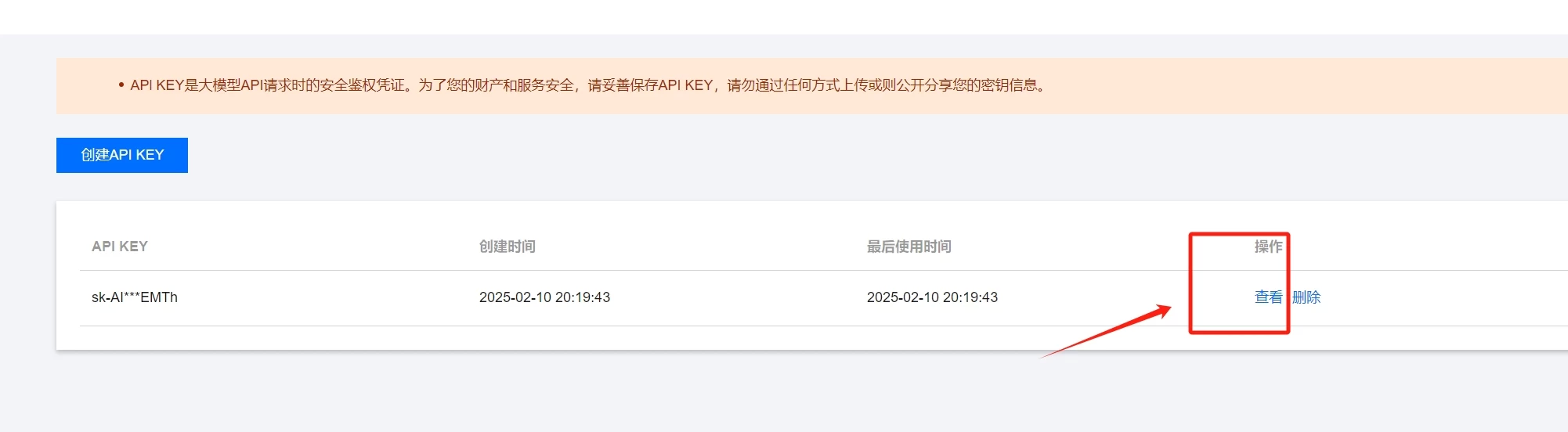
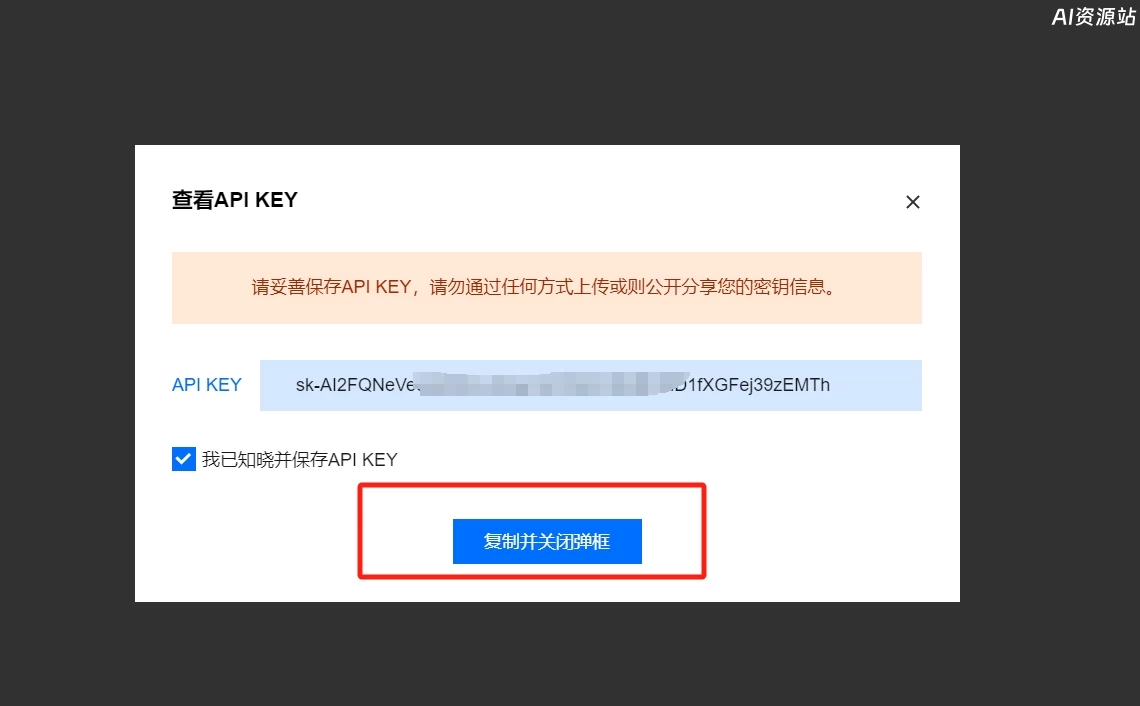
复制好刚才创建的key后,打开CherryStudio的设置页面
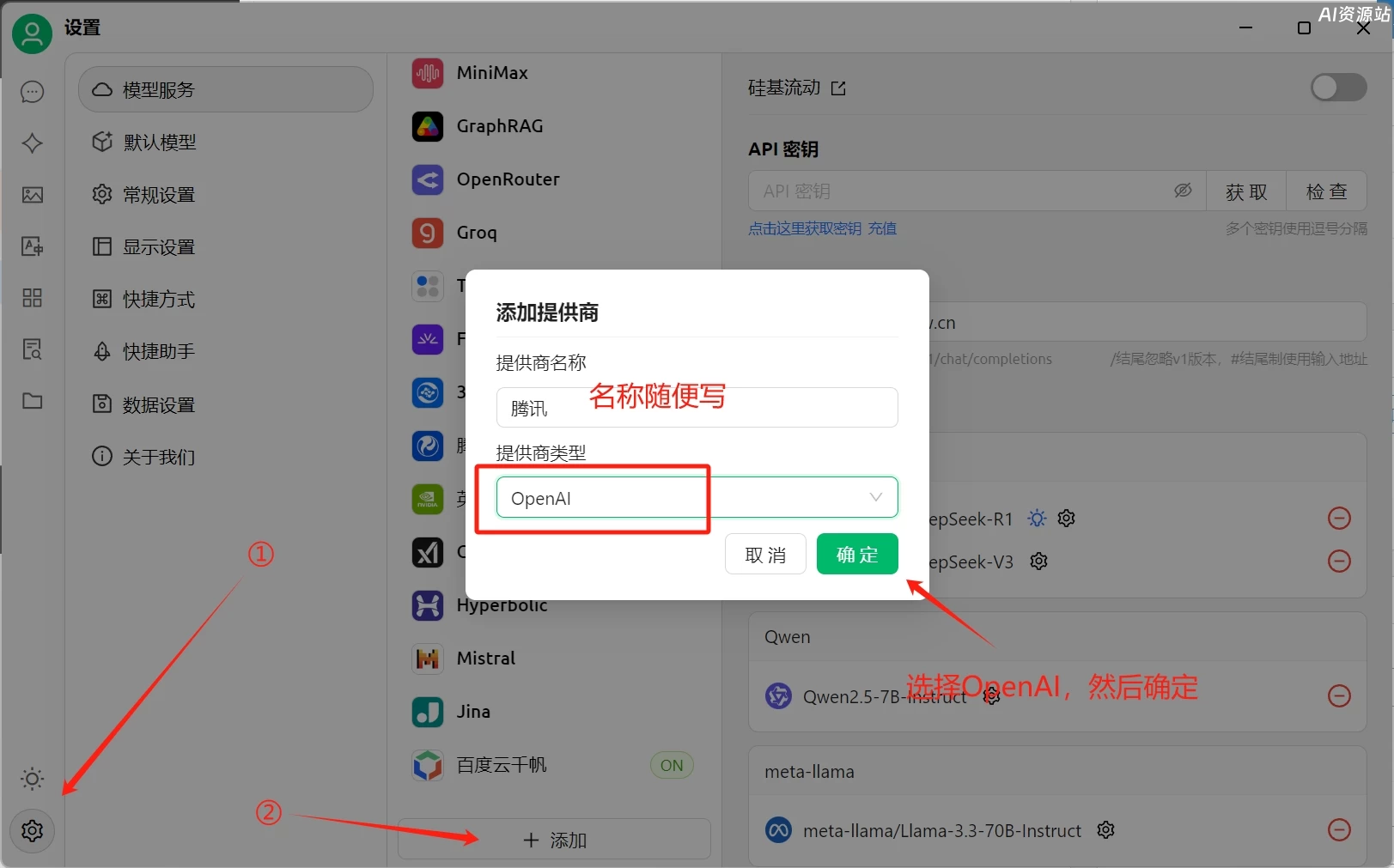

粘贴刚才复制的key,再填好API地址:https://api.lkeap.cloud.tencent.com
然后再点击下面的添加模型,填写deepseek-r1
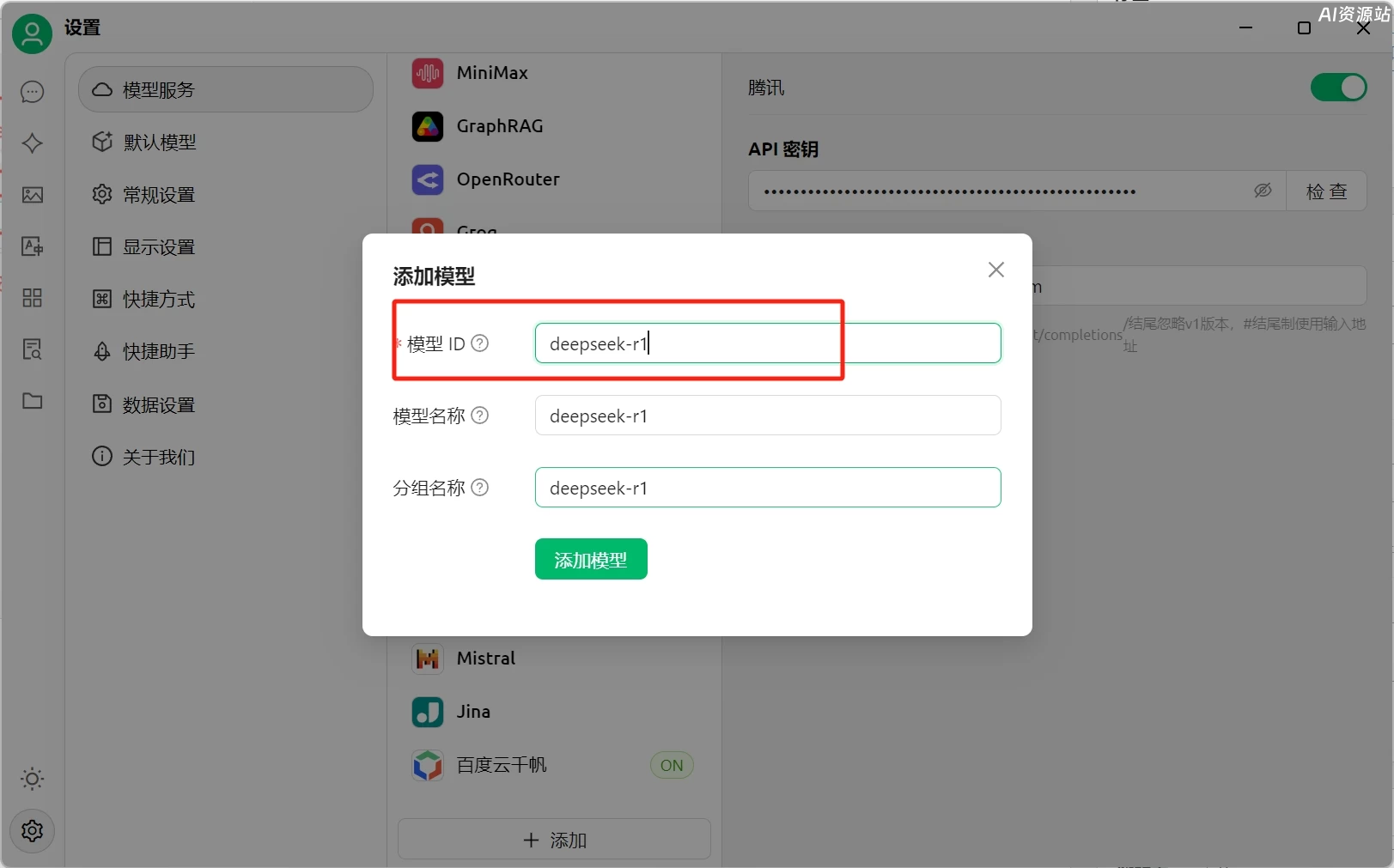
最后返回对话页面,选择刚刚创建的模型,即可正常使用了
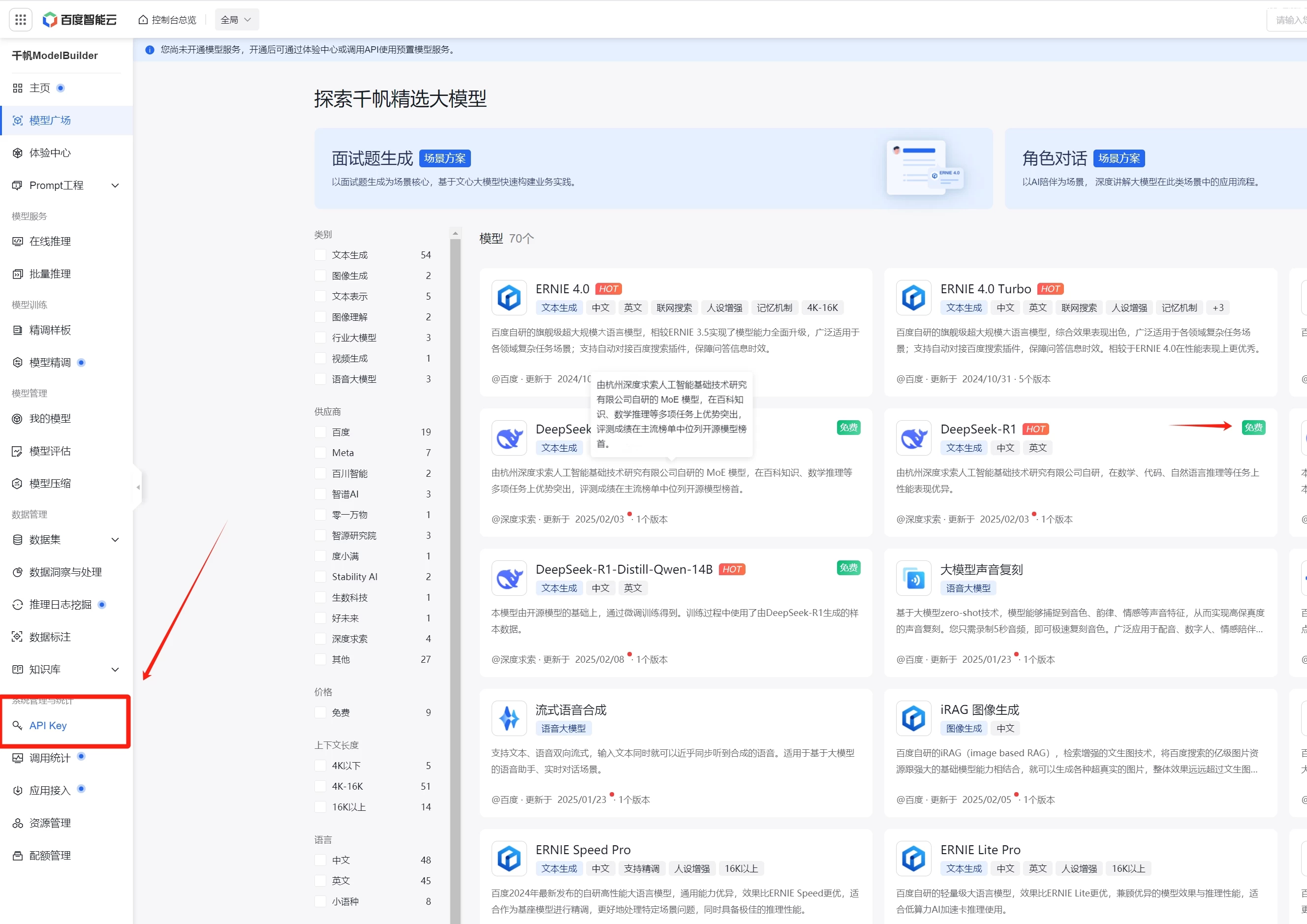
4.百度云:https://console.bce.baidu.com/qianfan/overview
目前免费,具体收费未知,需要实名认证
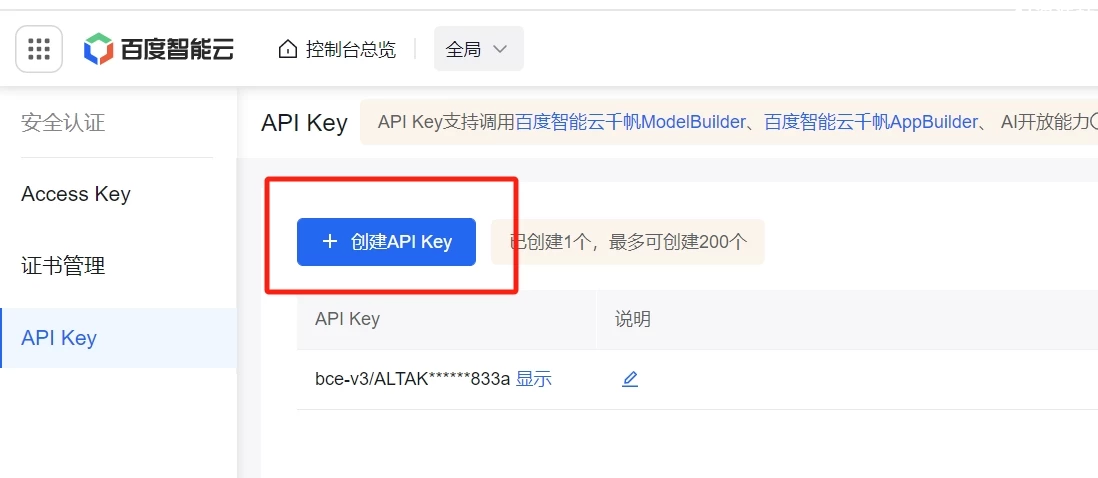
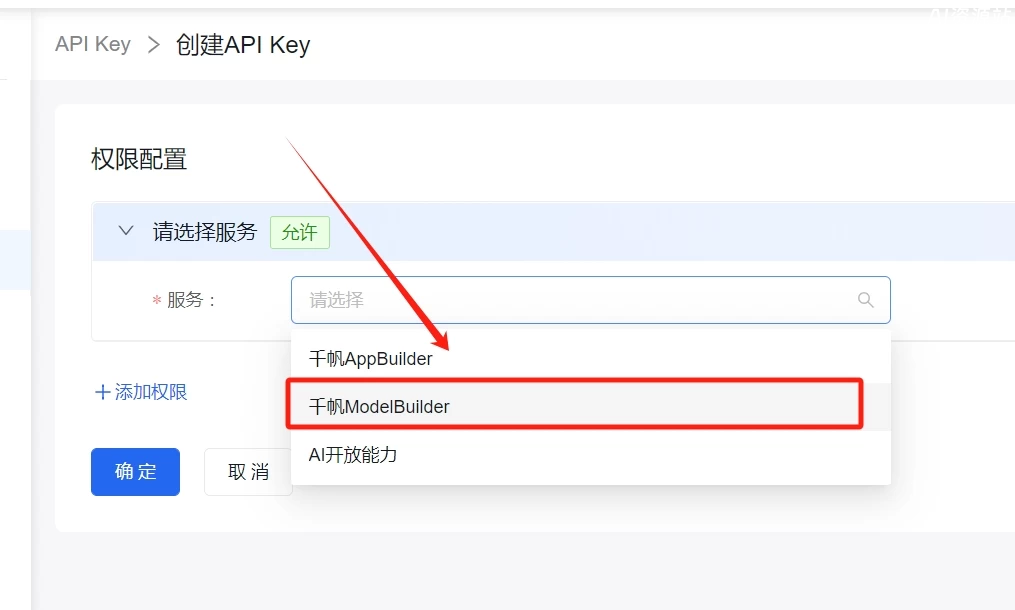
百度云API创建方式:↓
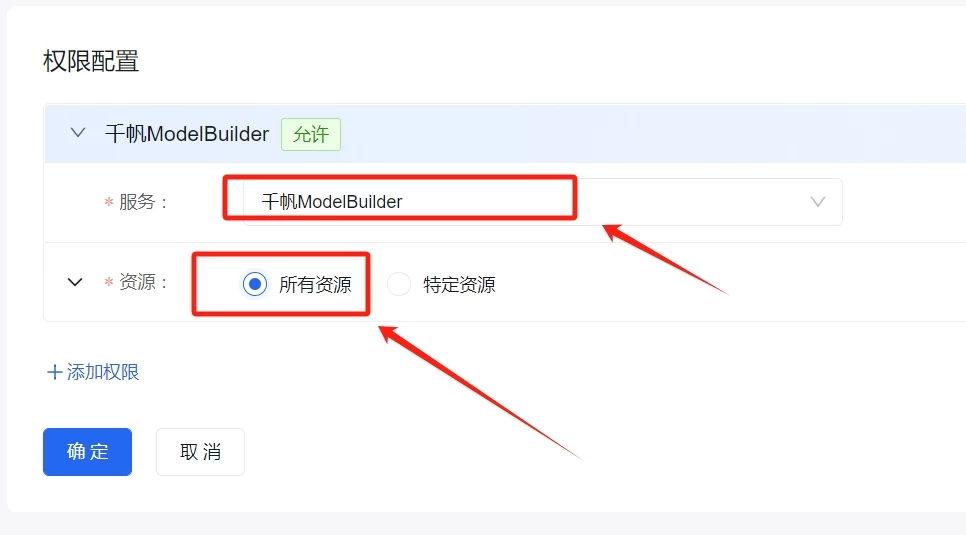

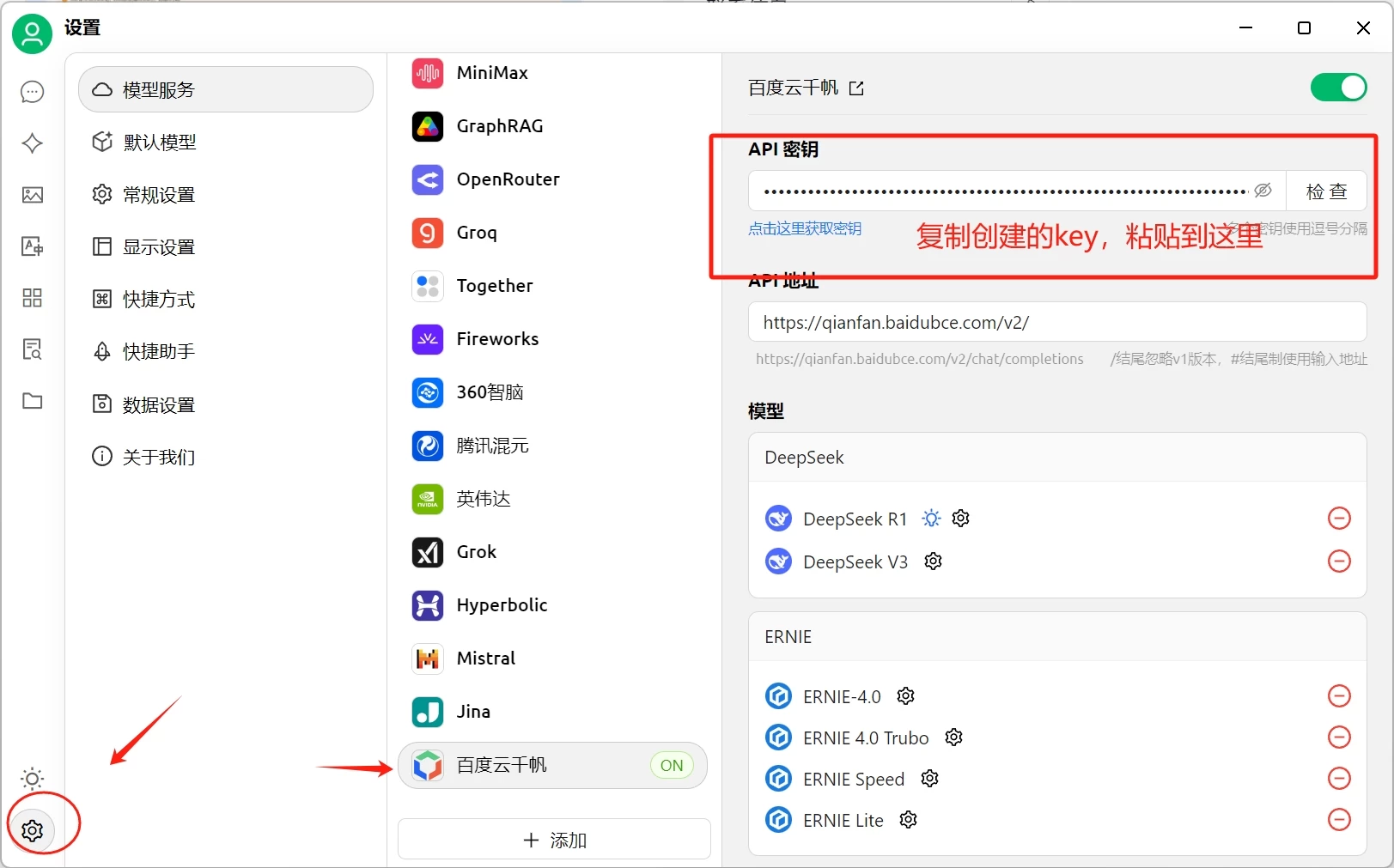
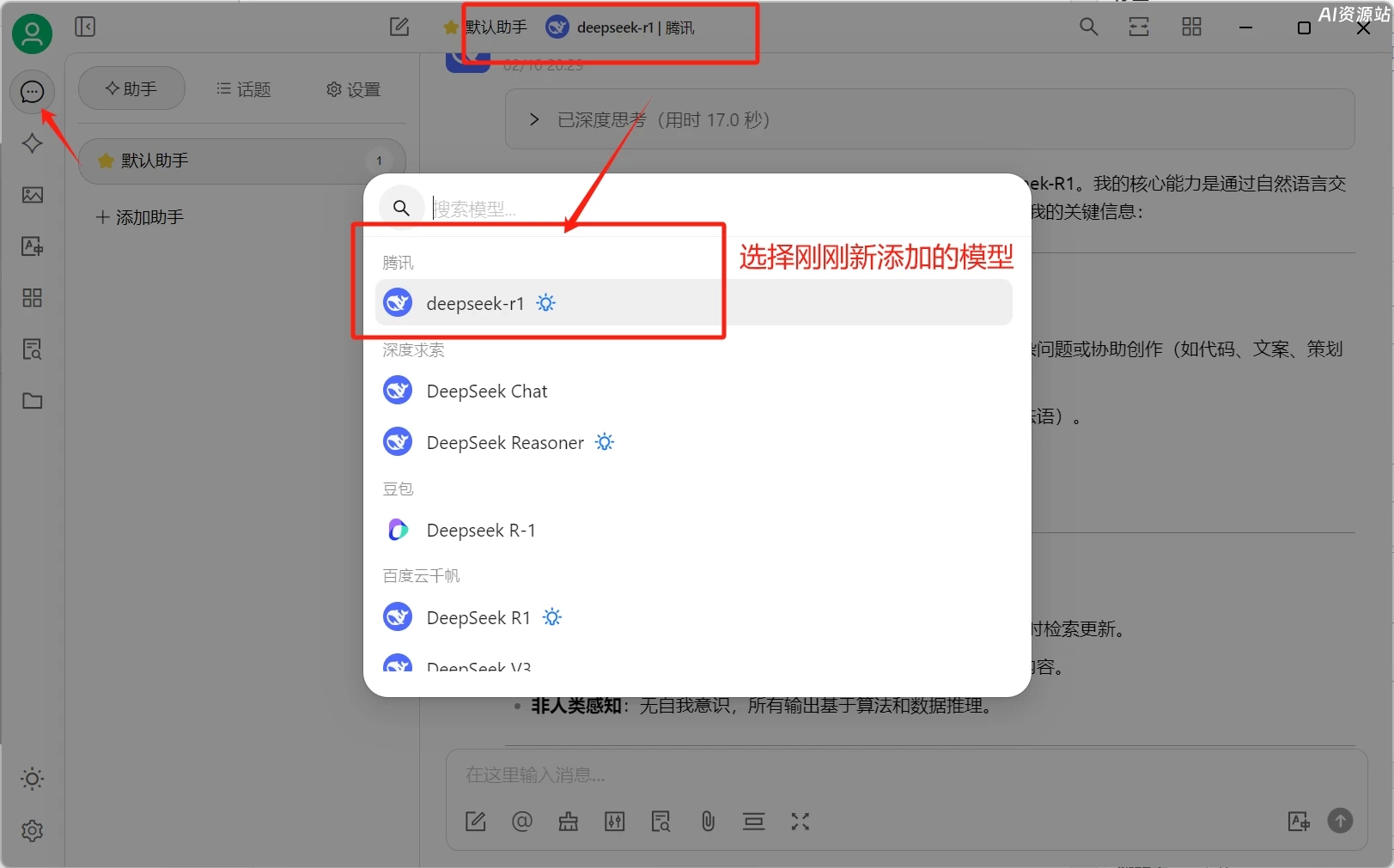
回到对话页面,选择刚才添加的百度云千帆里的deepseek 模型即可
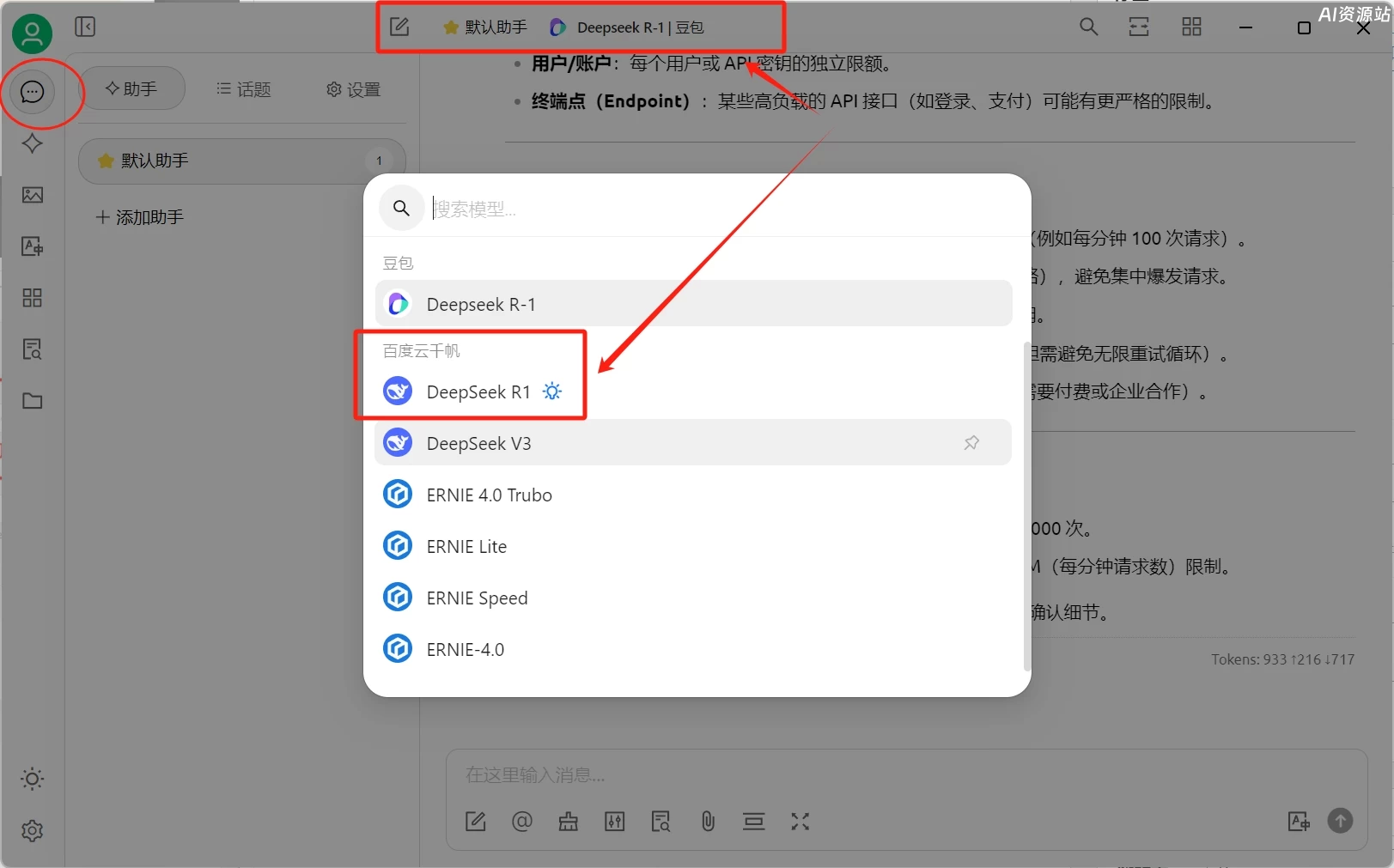
三、本地化部署Deepseek
个人是非常不推荐本地化部署的,因为部署后的实际使用效果确实一般,如果你想要提升体验效果,那就要看你的电脑配置了,这里给大家列出了deepseek R1不同的模型对电脑配置的最低需求:
| 模型版本 | 最低CPU要求 | 内存需求 | 显存需求 | 推理速度(tokens/s) | 精度保持率 | 最大上下文 |
|---|---|---|---|---|---|---|
| 1.5B | Intel i5-8500 | 8GB | 无需独立GPU | 60 (CPU) | 92% | 4k |
| 7B | Intel i7-10700 | 16GB | RTX 3060 12GB | 48 | 95% | 8k |
| 8B | Xeon E-2288G | 24GB | RTX 3080 10GB | 32 | 97% | 16k |
| 14B | Xeon Silver 4310 | 48GB | RTX 3090 24GB | 24 | 98% | 32k |
| 32B | Xeon Gold 6338N | 128GB | RTX 4090 24GB*2 | 18 | 99% | 64k |
| 70B | Xeon Platinum 8380 | 256GB | A100 40GB*4 | 9 | 99.5% | 128k |
| 671B | Xeon Max 9480 (8节点) | 2TB | H100 80GB*16 | 3 | 99.8% | 256k |
如何本地化部署?
1.安装ollama
打开ollama官网:https://ollama.com/,点击Download下载并安装ollama
安装好以后,键盘按win+r,输入cmd
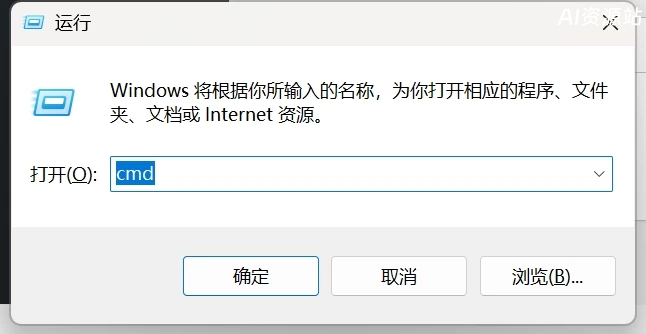
在窗口中输入ollama,如图所示,则表示ollama已经成功运行
安装好ollama后,我们来下载deepseek-r1模型
下载模型前,我们先来设置一下模型存放的文件夹,ollama默认下载的模型文件会存放在C盘,不设置的话C盘会爆满:
1.设置本地电脑的环境变量,在电脑左下角搜索中输入“系统变量”,然后打开“编辑系统环境变量”
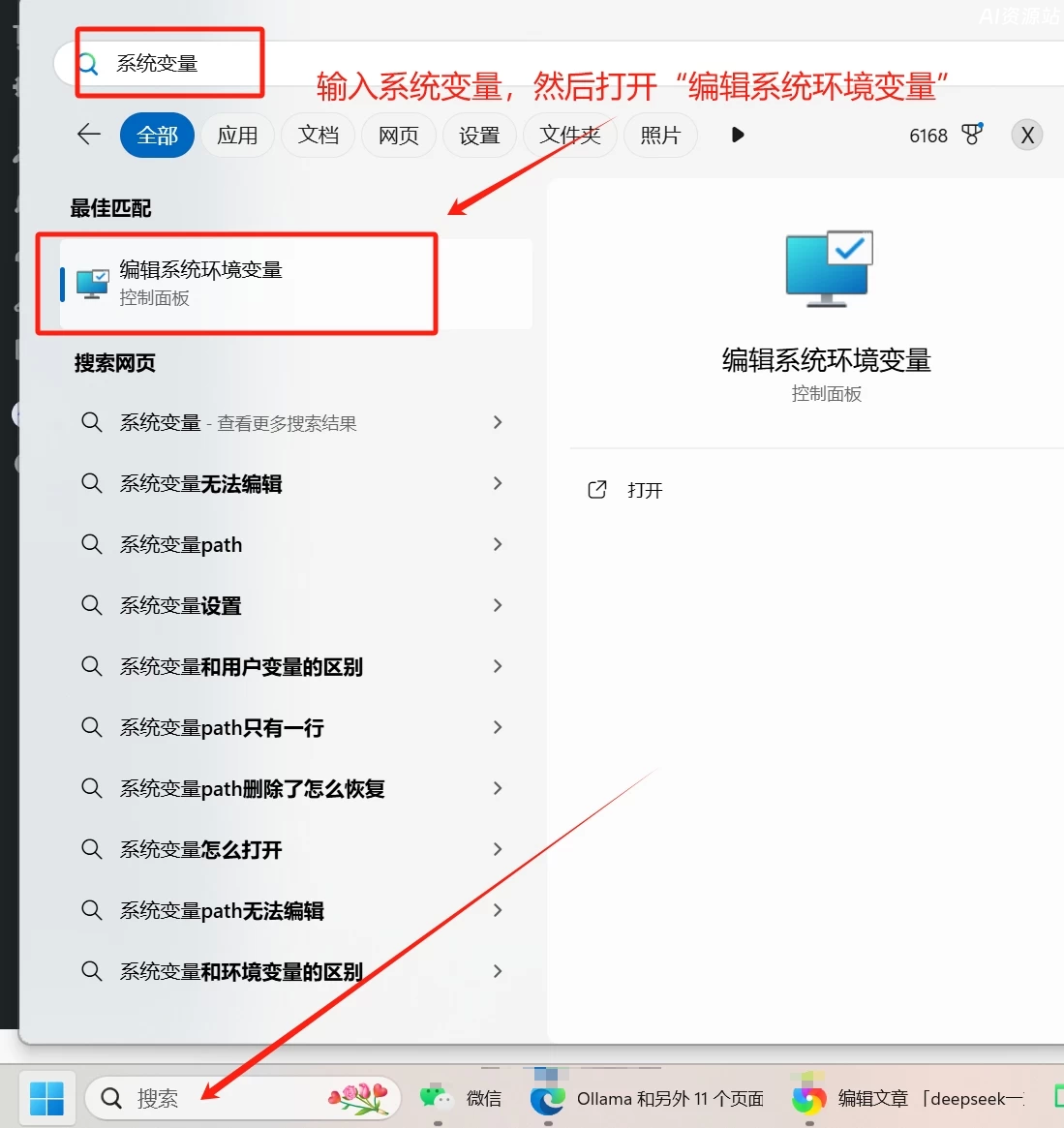
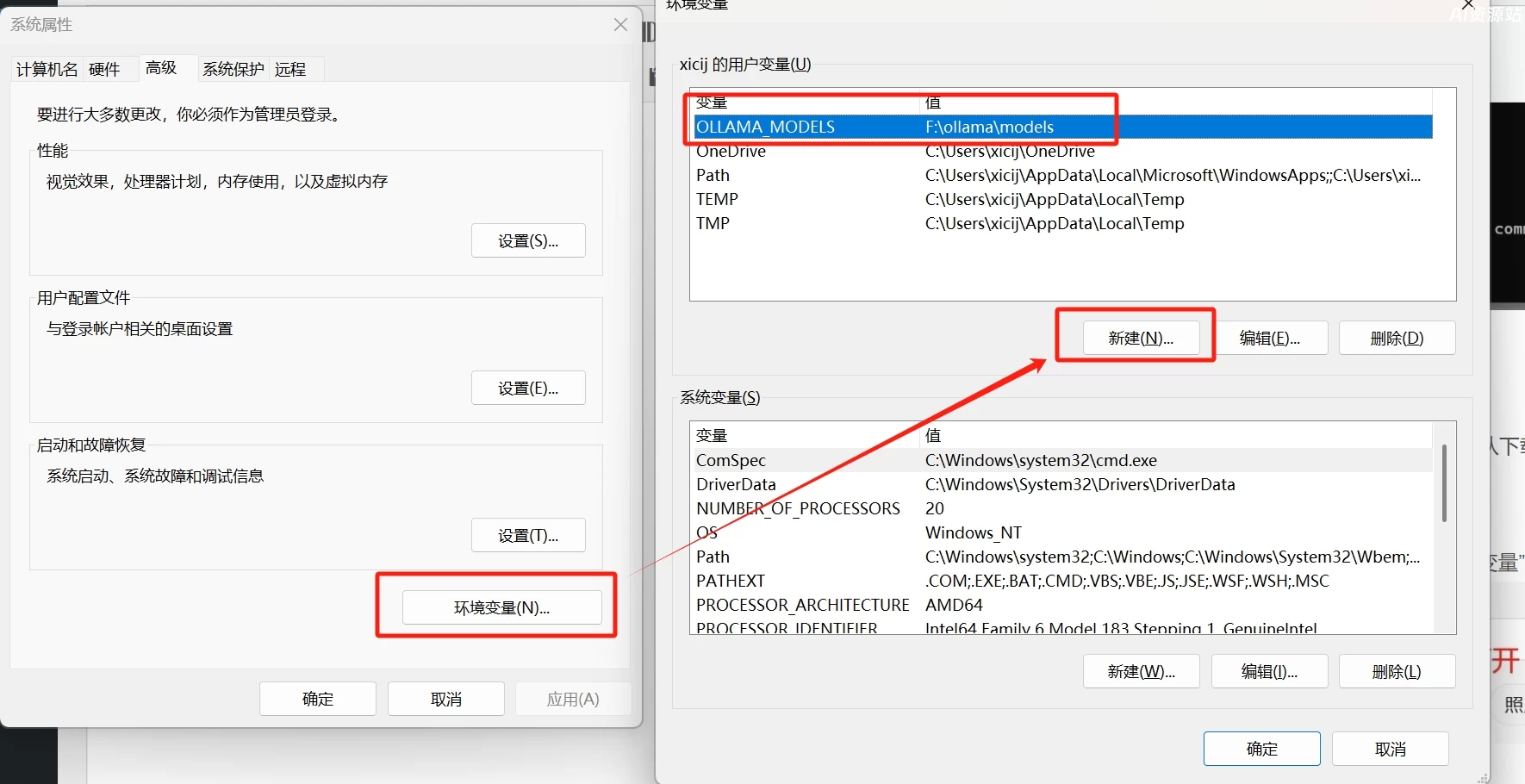
变量名:OLLAMA MODELS
变量值:F:\ollama\models(这是存放模型文件夹的路径,根据自己电脑实际情况填写)
变量值:F:\ollama\models(这是存放模型文件夹的路径,根据自己电脑实际情况填写)
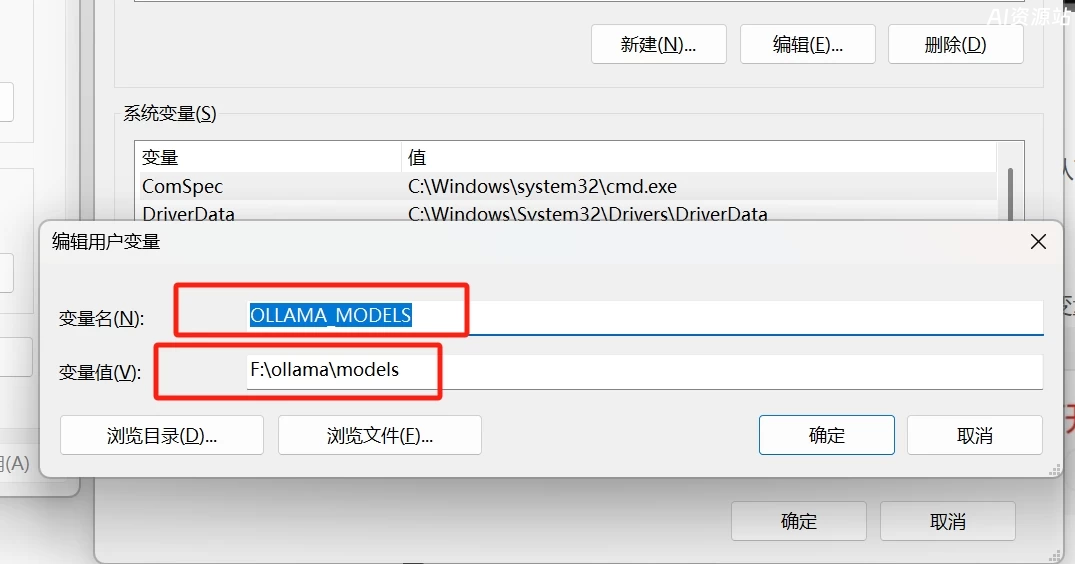
2、建议重启电脑确保环境变量生效
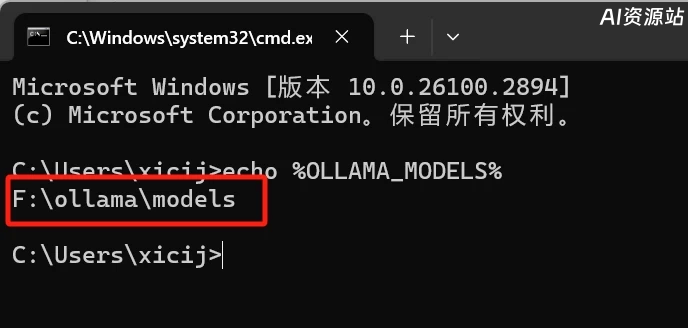
重启完电脑后,cmd中输入:echo %OLLAMA_MODELS%,如下图可以查看环境变量是否设置成功。
重启完电脑后,cmd中输入:echo %OLLAMA_MODELS%,如下图可以查看环境变量是否设置成功。
如果下载模型出现: Error: pul model manifest: open C:\Users\c\.olama\id_ed25519: The system cannot find the path specified.报错
可以尝试删除C盘下.olama目录,再将olama软件重启,再次运行下载命令,让 Olama 重新进行初始化;或者重启电脑再次运行下载命令,让 Ollama 重新进行初始化。
修改完模型的存放路径后,我们接下来就要下载deepseek R1模型了,在ollama官网搜索deepseek r1模型,
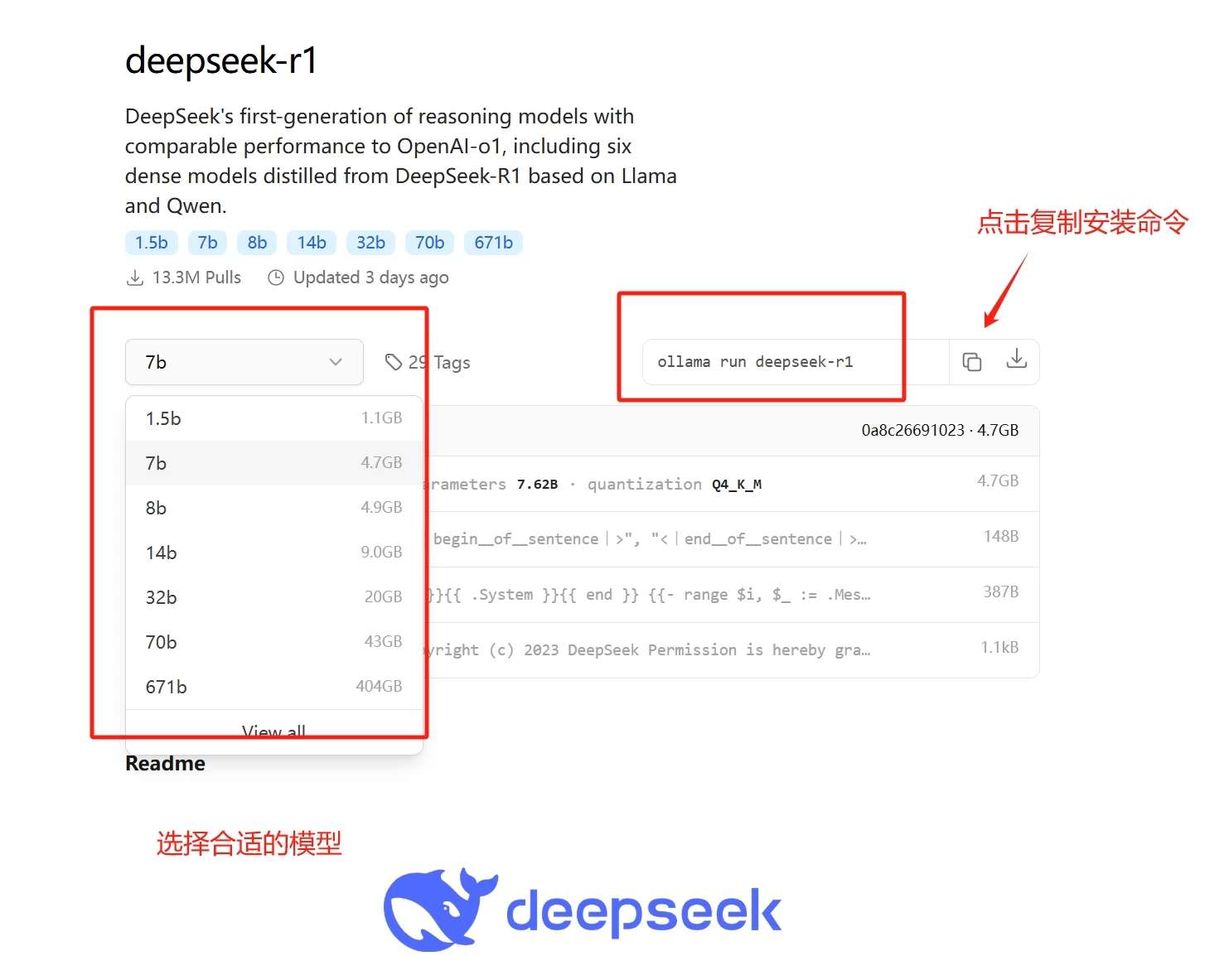
根据你的电脑配置,选择合适的模型,然后点击右侧的复制命令按钮;
复制好后,直接在cmd窗口中粘贴,敲回车就开始下载模型了,只要耐心 等待模型下载完成即可
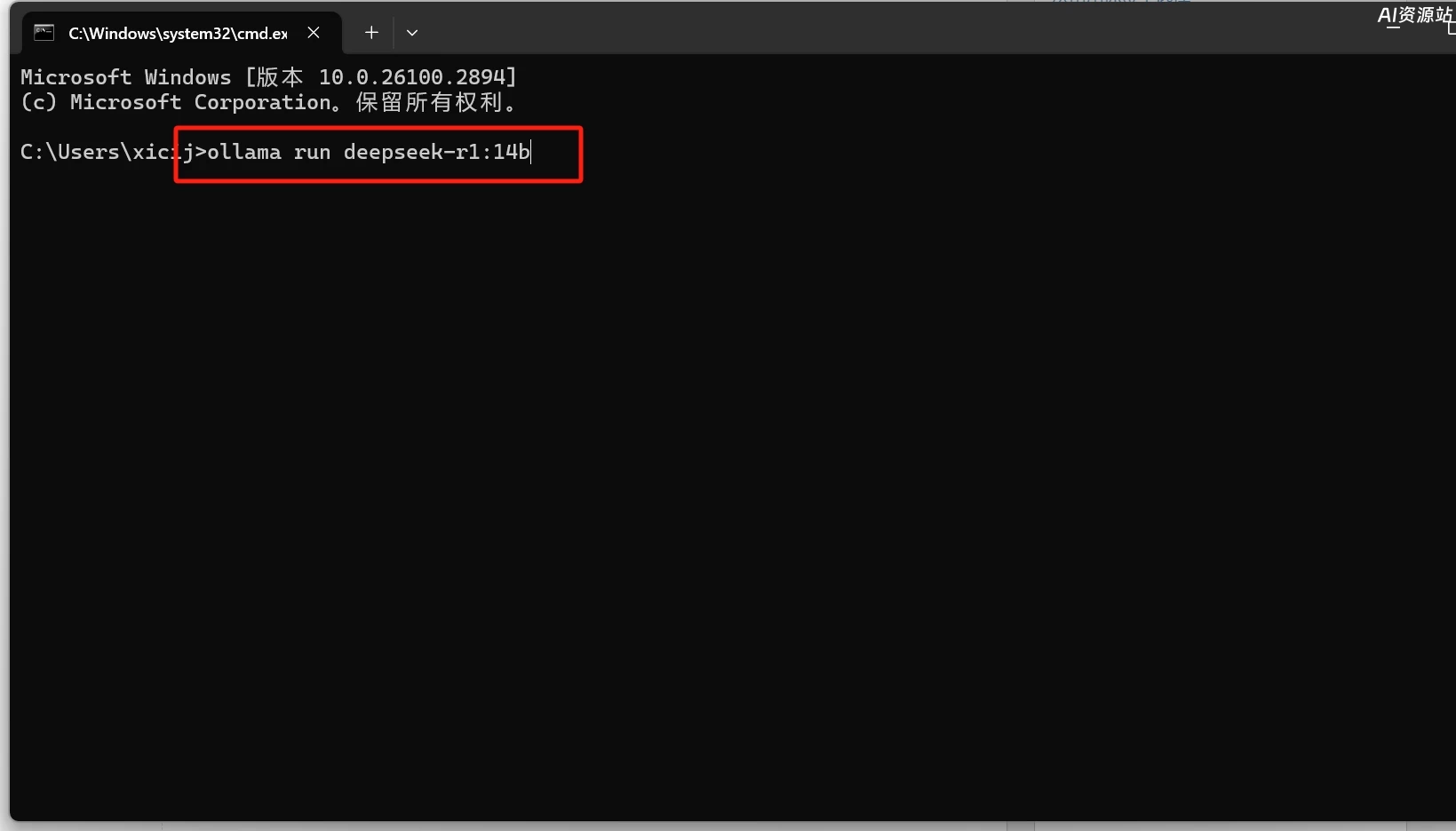
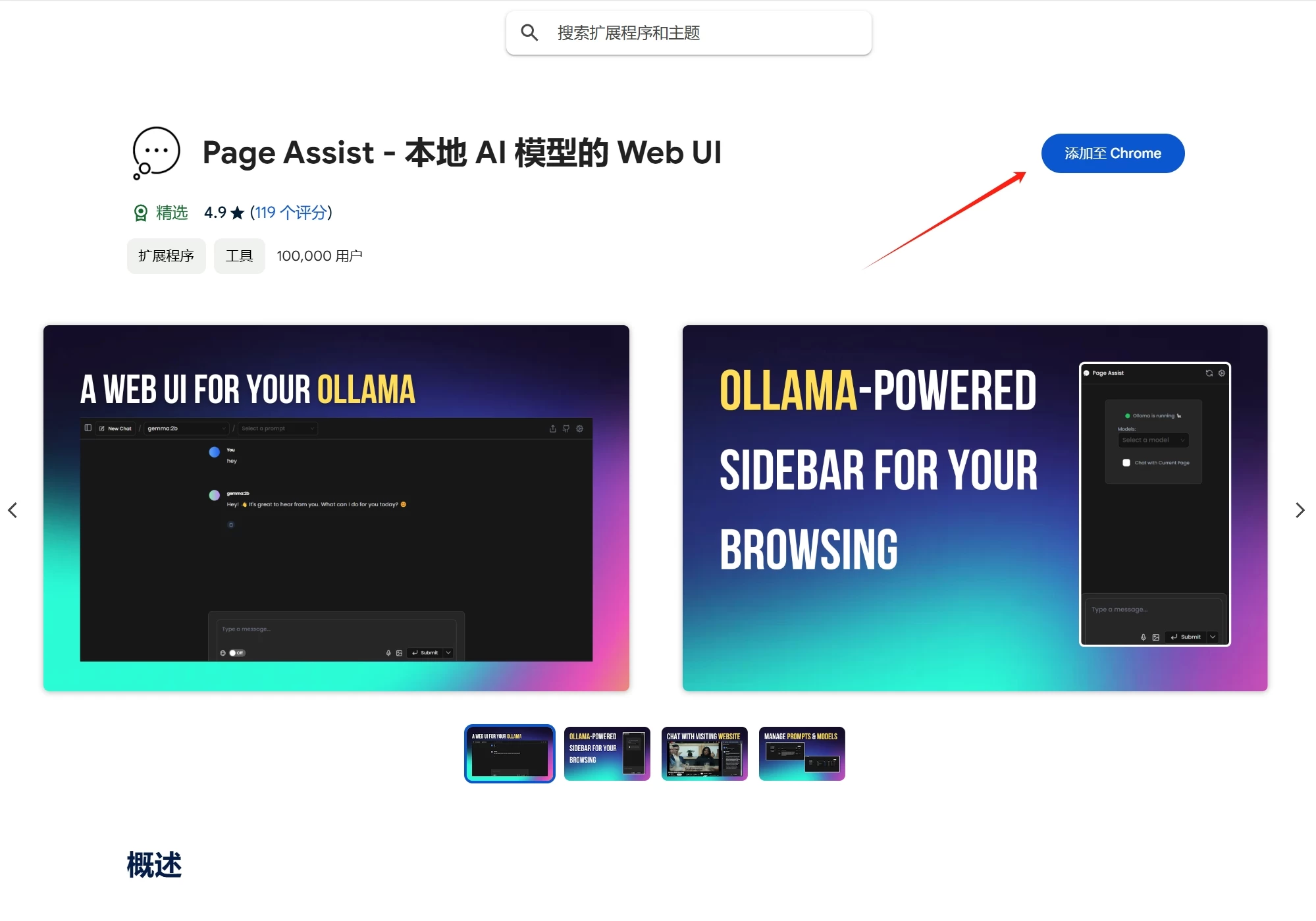
接下来打开谷歌或者edge浏览器,我们来安装一个本地模型的web ui的插件,
复制这个插件的网址:https://chromewebstore.google.com/detail/page-assist-%E6%9C%AC%E5%9C%B0-ai-%E6%A8%A1%E5%9E%8B%E7%9A%84-web/jfgfiigpkhlkbnfnbobbkinehhfdhndo 打开后直接安装插件
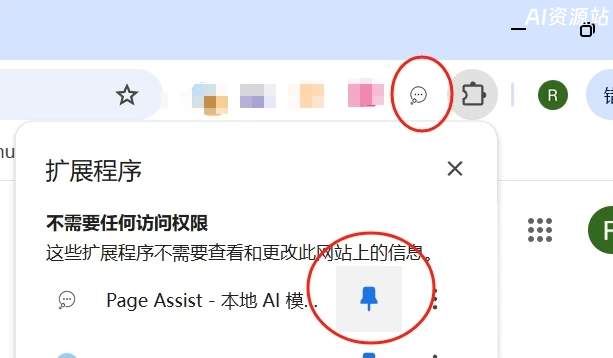
在浏览器右上角,打开白色的气泡图标,就可以打开web ui的页面了,然后设置一下语言
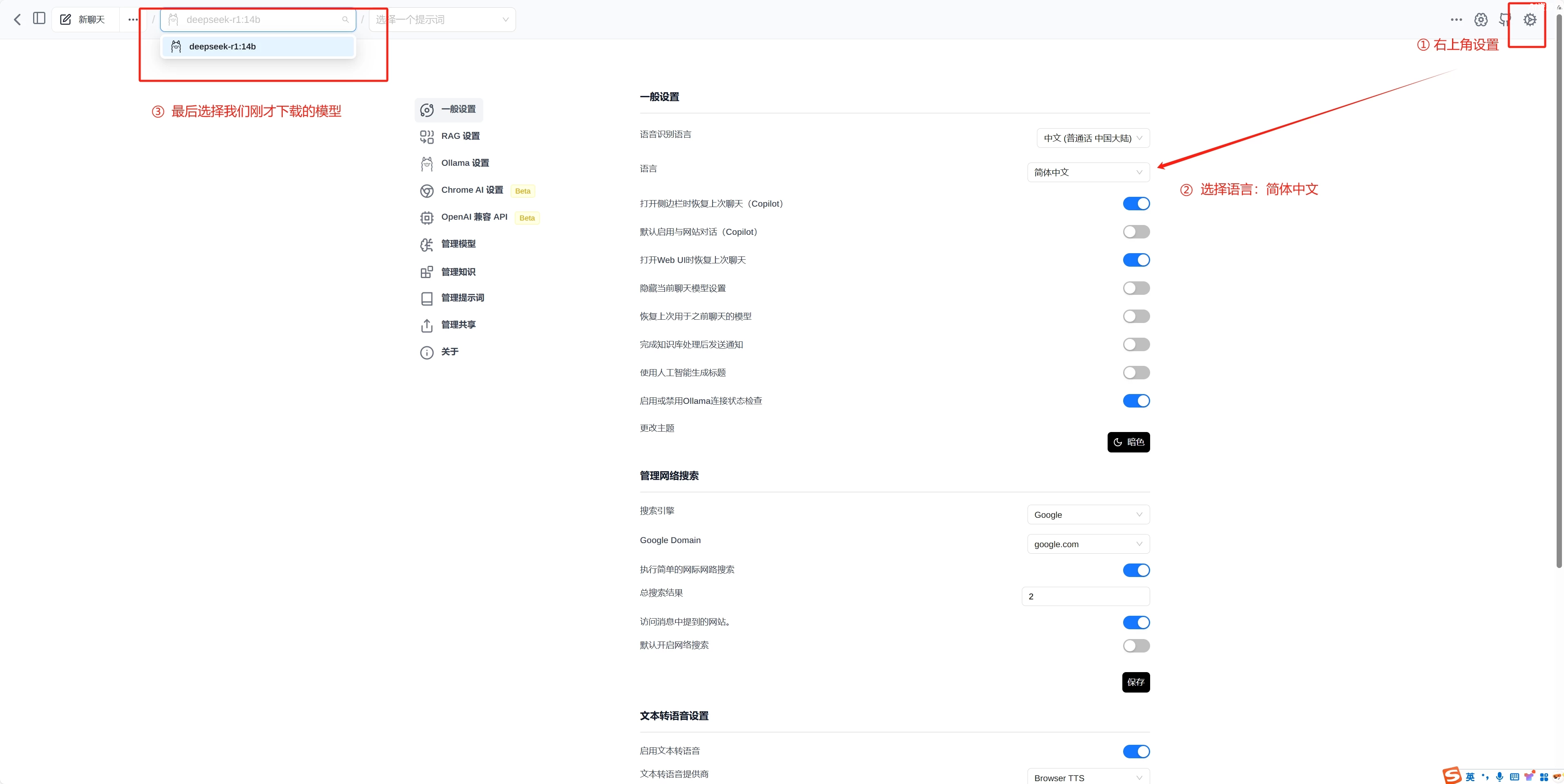
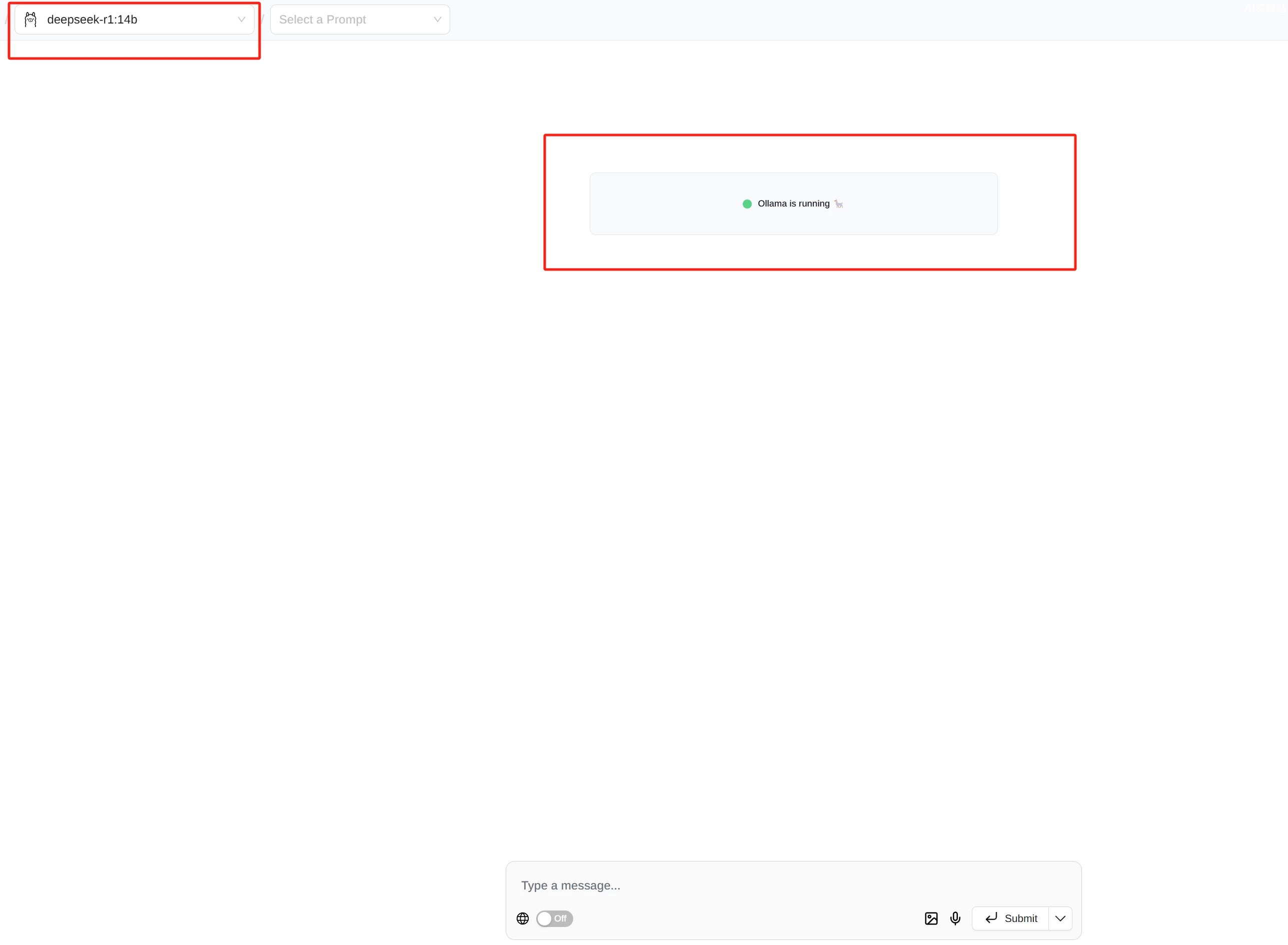
这样就可以正常使用了,我们的本地化部署也就完成了。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...